С нами с 03.06.13
Сообщения: 332
Рейтинг: 37

|
 Добавлено: 23/03/16 в 08:03 Добавлено: 23/03/16 в 08:03 |
A-Parser - 1.1.462 - цепочки заданий, сохранение JavaScript функций в пресете задания
Улучшения
- Добавлена возможность использовать цепочки заданий - запускать определенное задание после завершение текущего, с возможностью указать файл результатов первого задания, как файл запросов для следующего
- Теперь JavaScript функции можно сохранять в настройках задания, что позволяет включать их при экспорте задания
- При форматировании элементов массивов через метод .format теперь можно использовать все простые(Flat) переменные, которые выдает парсер или которые формируются используя Конструктор результатов
- В прокси чекер добавлена опция Load limit count, позволяющая задать максимальное число прокси для загрузки с источников
- В парсере
 Net::HTTP для опции Check content добавлен переключатель Match / Not Match позволяющий проверять не только наличие, но и отсутствие определенного контента на странице Net::HTTP для опции Check content добавлен переключатель Match / Not Match позволяющий проверять не только наличие, но и отсутствие определенного контента на странице
- Теперь файл задания не перезаписывается при отсутствии свободного места на диске
- В лог добавлена информация о версии парсера, количество свободной памяти и другая полезная информация
Исправления в связи с изменениями выдачи
- Исправлены
 SE::Yandex, SE::Yandex,  SE::Google SE::Google
Исправления
- В парсере SE::Google сниппеты и анкоры парсились с некорректной кодировкой при использовании Антигейта
- При использовании опции Конечный текст и кириллического имени файла результата конечный текст сохранялся в файл с неверной кодировкой в имени
- При использовании лога после постановки задания на паузу и продолжении работы лог переставал писаться, также при отключении логирования и попытке просмотра лога парсер мог упасть
- В Тестировщике заданий при закрытии окна с активным заданием появлялась ошибка
- В парсере
 SE::Yandex::Direct::Frequency некоторые фразы не обрабатывались при использовании аккаунтов, а также некорректно передавалось гео без использования аккаунтов SE::Yandex::Direct::Frequency некоторые фразы не обрабатывались при использовании аккаунтов, а также некорректно передавалось гео без использования аккаунтов
- Макрос $pagenum в парсере Net::HTTP переставал работать если после него были указаны символы
- Парсер
 SE::Google::TrustCheck не работал совместно с антигейтом SE::Google::TrustCheck не работал совместно с антигейтом
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 07/04/16 в 09:17 |
A-Parser - 1.1.481 - множество оптимизаций скорости, использование пресетов в цепочках и планировщике
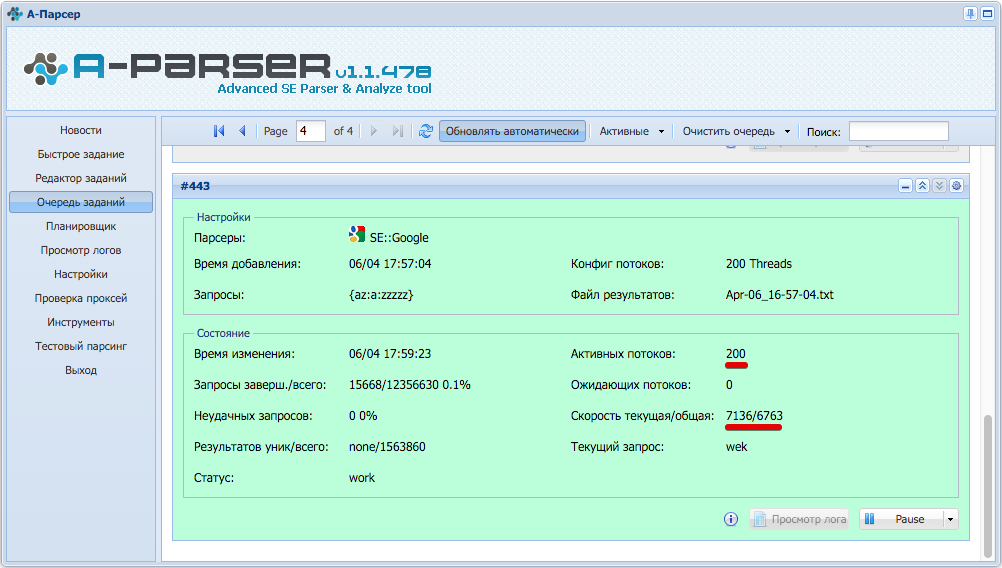
В этой версии был внедрен ряд качественных улучшений, призванных увеличить предельную скорость парсинга:
- Быстрая обработка UTF-8, прирост скорости на некоторых задачах до 1.5х
- Внедрен механизм анализа используемых переменных в результатах, что позволяет оптимизировать скорость извлекая только требуемые данные. Первым оптимизированным парсером стал SE::Google: двукратный прирост предельной скорости парсинга при сборе только ссылок(7000-10000 запросов в минуту, по 100 результатов на запрос, другими словами теперь можно получить 1 миллион ссылок за 1-1.5 минуты)
- Теперь информация о запросах $response формируется только по требованию
- Оптимизирована работа шаблонизатора при использовании множества парсеров в одном задании
Другие улучшения:
- Теперь при использовании опции "Запустить задание по завершению" используется имя пресета вместо номера задания из очереди
- В планировщике заданий также используется имя пресета, что позволяет очищать очередь без риска потерять сохраненные задания для планировщика
Исправления в связи с изменениями в выдачи:
- SE::Google - поиск по блогам, также увеличена скорость парсинга за счет изменения запросов
 SE::Yahoo, SE::Yahoo,  SE::DuckDuckGo, SE::DuckDuckGo,  SE::AOL SE::AOL
Исправления:
- В парсере
 Rank::Archive исправлена логика при обработке ошибки 403 Forbidden Rank::Archive исправлена логика при обработке ошибки 403 Forbidden
- Исправлено падение при изменении числа потоков в задании
- Исправлена поддержка TLS для некоторых сайтов
- Исправлено зависание задания при падении воркера
- Теперь задание можно остановить если оно находится в режиме ожидания слота
- Исправлена работа опции "Сохранять размер окна"
- Исправлена ошибка в
 HTML::LinkExtractor при работе опции Parse to level в случаях когда сайт отдал редирект на другую страницу HTML::LinkExtractor при работе опции Parse to level в случаях когда сайт отдал редирект на другую страницу
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 27/04/16 в 04:49 |
Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
13-й выпуск Сборника рецептов. В нем мы научимся сохранять результат в файл дампа SQL, который будет сразу готов для импорта в базу данных; познакомимся с очень полезным инструментом $tools.query, с помощью которого можно объединять несколько заданий в одно и делать другие интересные вещи; а также увидим еще несколько полезных рецептов.
Вывод результата в формате дампа SQL
С вопросом "можно ли сохранять результаты сразу в базу данных" очень часто обращаюся пользователи в техподдержку. И так, как на данный момент напрямую сохранять результаты в БД нет возможности (но планируется), то предлагаю вариант выводить их в файл дампа, а потом импортировать в базу данных. Как это делается - показано по ссылке выше.
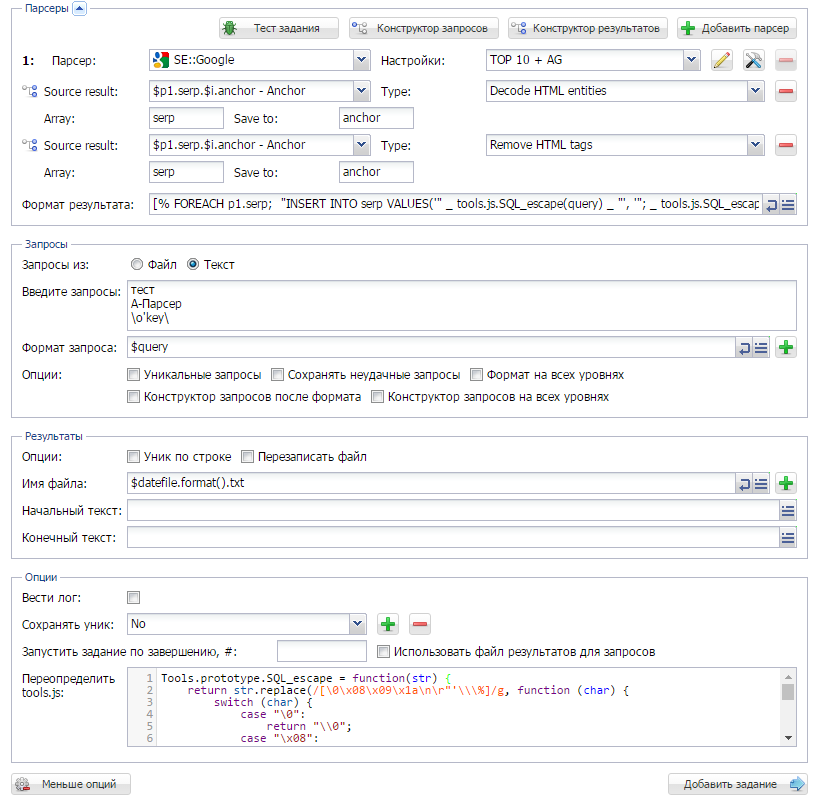 Обзор инструмента $tools.query
Обзор инструмента $tools.query
$tools.query довольно часто встречается в примерах на форуме. В А-Парсере этот инструмент появился уже больше года назад, но обзора по нему до этого времени не было выпущено. Поэтому мы исправляемся и по ссылке выше вы сможете ознакомиться с некоторыми его возможностями.
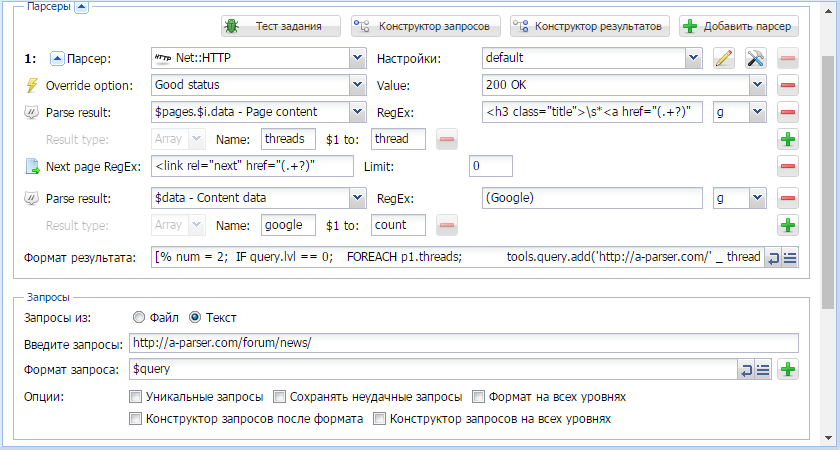 Еще несколько рецептов:
Еще больше различных рецептов в нашем Каталоге примеров!
Еще несколько рецептов:
Еще больше различных рецептов в нашем Каталоге примеров!
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 04/05/16 в 05:45 |
A-Parser - 1.1.500 - использование разных источников прокси в разных заданиях и парсерах
В этой версии проделана большая работа по улучшению проверки прокси и добавлению возможности использования разных источников прокси:
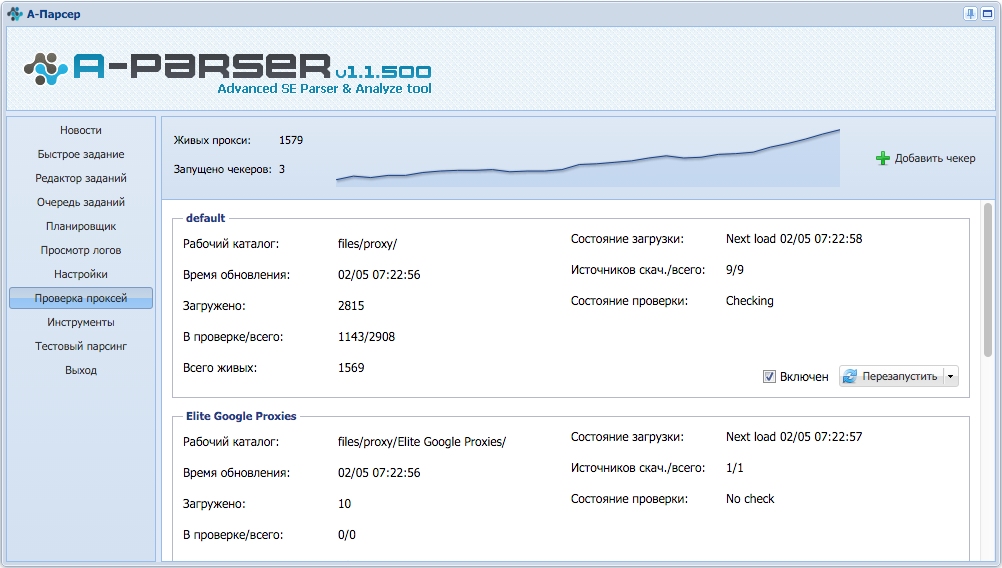
- Появилась возможность запускать сразу несколько прокси чекеров, каждый поддерживает собственные настройки и собственный рабочий каталог с возможностью указать различные источники проксей
- В настройках задания, появилась возможность указать прокси от каких чекеров должны использоваться(выбор между всеми или перечисление конкретных)
- Более того в одном задании каждый парсер может использовать различные источники прокси
- Добавлен график живых прокси и статистика по обработке источников
- Уменьшено потребление памяти при большом числе живых прокси
- В API теперь возможно получить список всех живых прокси, а также список прокси для конкретных прокси чекеров
Благодаря этим нововведениям появилась возможность раздельной работы с разными прокси серверами, когда одни прокси подходят для парсинга сайтов, другие лучше для парсинга выдачи поисковых систем, а третьи могут быть "заточены" под определенный сервис
Другие улучшения:
- Для парсера
 Rank::CMS добавлена опция эмуляции браузера, она включена по умолчанию и повышает процент распознавания многих CMS Rank::CMS добавлена опция эмуляции браузера, она включена по умолчанию и повышает процент распознавания многих CMS
- В редакторе заданий появилась возможность сворачивать парсеры, что позволяет удобнее работать с большими заданиями
Исправления в связи с изменениями в выдачи:
 Rank::MajesticSEO, SE::Yandex, Rank::Archive, Rank::MajesticSEO, SE::Yandex, Rank::Archive,  SE::Google::Images, SE::Google::TrustCheck, SE::Google::Images, SE::Google::TrustCheck,  SE::Yandex::Catalog SE::Yandex::Catalog
Печальная новость коснулась  SE::Google::pR - Google прекратил отображать PageRank для сайтов, но у нас в арсенале есть множество парсеров для гораздо более точной оценки рейтинга домена!
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 13/05/16 в 11:41 |
A-Parser: видео урок - сбор отзывов о компании
Денис Бартаев рассказывает, как собрать отзывы о компании в необходимом регионе:
- Парсинг отзывов с популярного сервиса
- Работа с парсером Net::HTTP, переход по сайту в глубину
- Использование конструкторов запросов и результатов
- Получение нескольких элементов контента одним регулярным выражением
- Работа с асинхронными запросами в A-Parser
- Просмотр результата в табличном виде в Excel
Подписывайтесь на наш канал!
Оставляйте в комментариях свои идеи и пожелания для будущих видео
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 25/05/16 в 08:51 |
1.1.532 - парсинг регистратора в Whois, множество исправлений
Улучшения
- В парсере
 Net::Whois добавлен парсинг названия регистратора домена Net::Whois добавлен парсинг названия регистратора домена
Исправления в связи с изменениями в выдачи
 SE::YouTube, SE::AOL, SE::YouTube, SE::AOL,  SE::Dogpile, SE::Yandex SE::Dogpile, SE::Yandex
Исправления
- Исправлено падение при использовании JavaScript(tools.js) на Windows, также исправлена некорректная работа на Linux
- Исправлена проблема с логином на некоторых аккаунтах Яндекса
- Исправлено определение ранка в парсере
 Rank::Alexa для доменов с www. Rank::Alexa для доменов с www.
- Исправлена работа с некоторыми доменными зонами в парсере Net::Whois, а также отображение статуса для некоторых зон
- Исправлено падение Rank::CMS при использовании опции -nofork
- Исправлены проблемы в работе нового прокси чекера: отключение чекера при изменении настроек, переопределение чекера в задании, а также проблема с отображением в некоторых браузерах
- Исправлена работа опции Prepend/Append text в некоторых случаях
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 08/06/16 в 10:16 |
A-Parser - 1.1.566 - кэширование запросов, удобная работа с настройками, множество улучшений

Улучшения
- Теперь для парсеров Net::HTTP,
 HTML::TextExtractor, HTML::LinkExtractor, Rank::CMS кэшируются одинаковые HTTP запросы при использовании любой комбинации из этих парсеров в одном задании, что исключает выполнение повторных запросов к одному URL, как следствие растет скорость, уменьшается нагрузка на целевые сайты HTML::TextExtractor, HTML::LinkExtractor, Rank::CMS кэшируются одинаковые HTTP запросы при использовании любой комбинации из этих парсеров в одном задании, что исключает выполнение повторных запросов к одному URL, как следствие растет скорость, уменьшается нагрузка на целевые сайты
- Добавлена опция Max connections per host позволяющая ограничить максимальное число одновременных подключений к одному домену/IP
- Добавлена опция Global proxy ban позволяющая расшарить статистику по бану проксей между заданиями
- В парсере HTML::LinkExtractor улучшено отображение табличных данных и списков
- В парсере
 SE::Yandex::WordStat добавлена возможность указать минимальную частотность для добавления запроса на вложенный парсинг SE::Yandex::WordStat добавлена возможность указать минимальную частотность для добавления запроса на вложенный парсинг
- В парсере SE::Yandex добавлена опция Parse all results позволяющая автоматически обходить ограничение на размер выдачи и собирать гораздо больше результатов
- В редакторе заданий добавлена функция Copy overrides позволяющая копировать настройки из одного парсера в другой
- В редакторе заданий добавлена функция Save overrides to preset позволяющая создать новый пресет на основе переопределенных значений
- При просмотре логов с опцией "Только неудачные" теперь отображаются только те потоки, в которых были неудачные запросы
- При использовании xPath совместно с сохранением отдельных запросов в один массив данные заполняются равномерно
- В очереди заданий добавлена дата последнего изменения задания при отображении в компактном виде
- В очереди заданий добавлена возможность скачать файл результатов при незавершенном парсинге
- При использовании опции "Сохранять неудачные запросы" теперь дополнительно сохраняются оригинальные запросы для всего задания
- Добавлена опция Report captcha - распознанные Google каптчи отправляются на наш сервер для анализа, включена по умолчанию
Исправления в связи с изменениями в выдаче
- SE::Yandex,
 Rank::DMOZ, SE::AOL Rank::DMOZ, SE::AOL
Исправления
- Исправлена проблема с большим потреблением памяти на ОС Windows
- Исправлено неверное сохранение параметра уникализации в некоторых случаях
- Не работала замена на группы в регулярных выражениях в Конструкторе запросов
- В парсер HTML::LinkExtractor исправлен парсинг ссылок с пробелами
- Исправлена проблема с отображением заданий в очереди с большим числом запросов добавленных через текстовое поле
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 23/06/16 в 05:14 |
A-Parser: видео урок - парсим Rambler с XPath
Денис Бартаев рассказывает, как в несколько кликов создать парсер любой поисковой системы на примере Rambler.ru. Мы получим всю необходимую информацию: ссылки, анкоры, сниппеты, число результатов, связанные ключевые слова и проверку на опечатку в запросе.
В уроке рассмотрены
- Использование XPath для создания кастомного парсера
- Обход капчи без использования Antigate
- Использование Template toolkit для форматирования результата
- Объединение результатов парсинга в массив объектов с полями, связанными по индексу
Подписывайтесь на наш канал!
Оставляйте в комментариях свои идеи и пожелания для будущих видео
|
|
|
|
| |
С нами с 18.05.07
Сообщения: 8329
Рейтинг: 4007
|
| Добавлено: 23/06/16 в 16:14 |
| A-Parser Support писал: | | Оставляйте в комментариях свои идеи и пожелания для будущих видео |
Пожелание - делать ролики почаще и для более низкого уровня знаний 
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 06/07/16 в 09:37 |
A-Parser - 1.1.582 - множество исправлений поисковых систем
Улучшения
- В очереди заданий теперь запоминается текущая страница отдельно для активных и завершенных задач
- Добавлена возможность вывести время выполнения каждого запроса
Исправления в связи с изменениями в выдаче
- SE::Yandex,
 SE::Bing, SE::Bing,  SE::Yandex::Register, SE::Yandex::Register,  SE::Comcast, SE::Comcast,  SE::DisconnectMe, SE::DisconnectMe,  SE::Bing::Translator, SE::Bing::Translator,  Rank::LinkPad, SE::DuckDuckGo, SE::Yandex::Direct::Frequency Rank::LinkPad, SE::DuckDuckGo, SE::Yandex::Direct::Frequency
Исправления
- Улучшена обработка кодировки текста в HTML::TextExtractor
- В очереди заданий в некоторых случаях могли не отображаться кнопки управления заданием
Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
14-й выпуск Сборника рецептов. Сегодня мы научимся делать кастомные парсеры с помощью XPath, будем анализировать страницы сайта и попробуем делать комбинированные пресеты. Кроме этого ниже обновление 2-х самых популярных пресетов и небольшой сюрприз  Поехали!
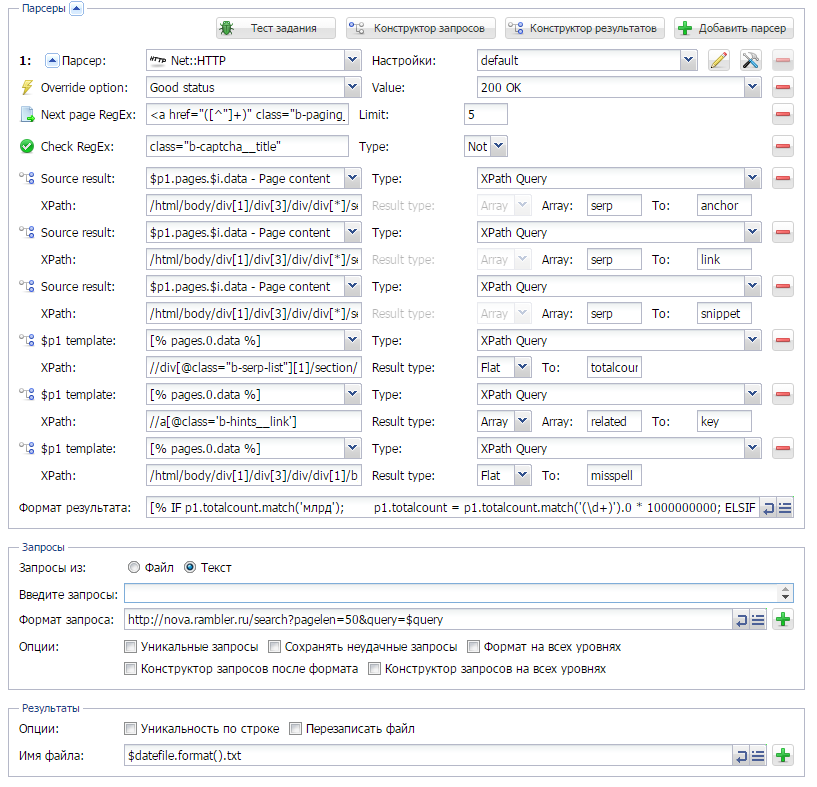
Быстрое создание кастомного парсера поисковой системы с помощью XPath
В A-Parser есть парсеры для большинства популярных поисковых систем. Но реализовать и поддерживать парсеры для абсолютно всех существующих поисковиков очень сложно, поэтому нам на помощь приходит Net::HTTP с его замечательной возможностью парсить практически все. В данной статье речь пойдет о том, как с помощью XPath и Net::HTTP довольно быстро и легко создать кастомный парсер почти любой поисковой системы. Подробности - по ссылке выше.
 Анализ всех страниц сайта
Анализ всех страниц сайта
Администраторы сайтов и SEO-специалисты довольно часто сталкиваются с задачей анализа и мониторинга всех страниц сайта. Ранее мы уже публиковали Универсальный чекер страниц, который позволяет проверить доступность страниц на сайте. Теперь мы предоставляем вашему вниманию пресет для анализа всех страниц, который выводит глубину, время ответа, код и статус ответа, размер страницы и, если есть редирект, то конечный адрес редиректа. Все детали и пресет - по ссылке выше.
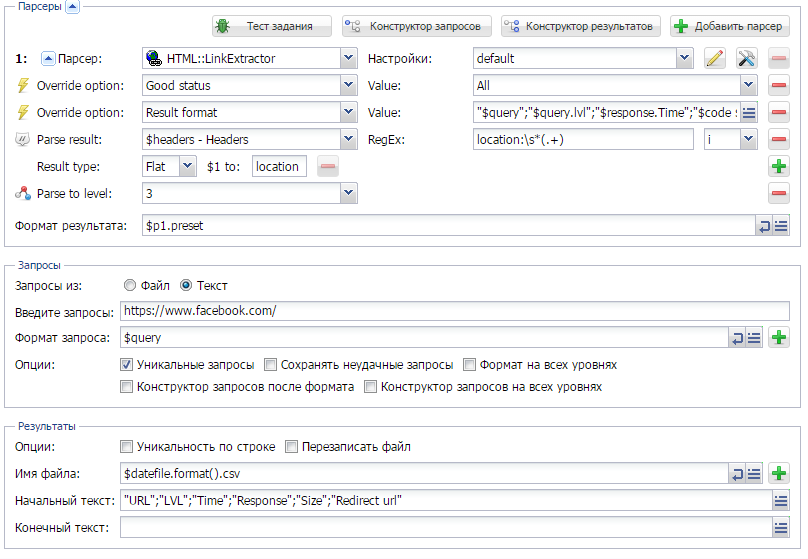 Как сделать парсинг и скан сайтов в одном пресете
Как сделать парсинг и скан сайтов в одном пресете
Возможность использовать несколько парсеров в одном задании - это одно из преимуществ А-Парсера. Простая демонстрация такого функционала показана по ссылке выше.
 Кроме этого:
Кроме этого:
- Обновлен пресет парсинга Авито
- По многочисленным просьбам полностью переделан пресет парсинга 2GIS. Теперь он еще быстрее! А для тех, кто внимательно читает наши статьи - в посте есть небольшой подарок: полная база 2GIS.
Еще больше различных рецептов в нашем Каталоге примеров!
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 20/07/16 в 09:37 |
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 17/08/16 в 06:11 |
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 05/09/16 в 15:00 |
A-Parser - 1.1.626 - парсер Яндекс картинок, поддержка каптчи при логине в Яндекс, удаление нерабочих аккаунтов

В версии 1.1.626 добавлена поддержка каптчи при логине в Яндекс аккаунт в парсерах SE::Yandex, SE::Yandex::WordStat и SE::Yandex::Direct::Frequency:

Также для этих парсеров добавлена настройка Remove bad accounts, которая автоматически удаляет аккаунты с неверным логин/паролем или требующие подтверждения по телефону. Опция включена по умолчанию
Добавлен новый парсер картинок  SE::Yandex::Images, поддерживает все фильтры(размер, ориентация, тип, цвет, тип файла...). Как известно Яндекс отлично индексирует все картинки для взрослых - отличный способ набрать контента для своих доров/тюбов. В дополнении есть возможность выставить безопасный поиск
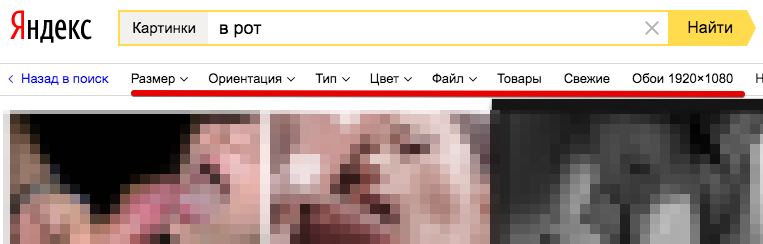
Парсер Яндекс картинок также поддерживает работу с антигейтом(anti-captcha, rucaptcha, CapMonster - любой сервис с поддержкой API антигейта)
Исправления в связи с изменениями в выдачи
- SE::DuckDuckGo
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 20/09/16 в 07:16 |
Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
15-й выпуск Сборника рецептов. В нем мы будем парсить Google PageSpeed Insights, который позволяет оценивать скорость загрузки, юзабилити сайтов и даже получать их скриншоты; сделаем кастомный парсер Яндекс.Картинок и научимся получать полные ссылки из выдачи Baidu. Поехали!
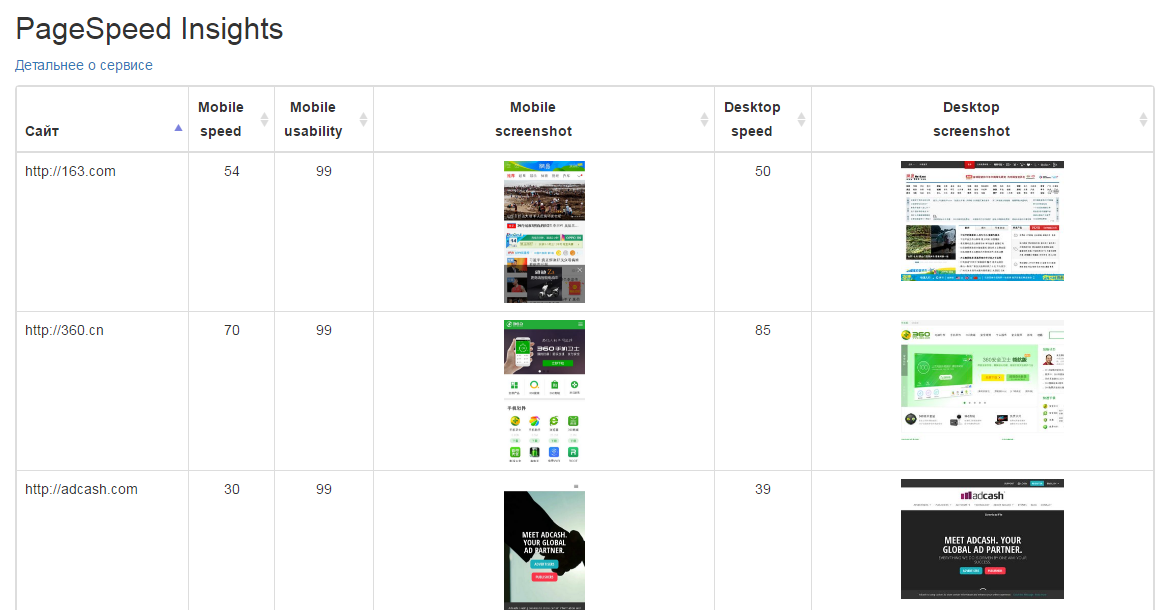
Анализ скорости загрузки и юзабилити сайтов
У Google есть довольно неплохой сервис PageSpeed Insights, который измеряет скорость загрузки веб-страниц, оценивает их юзабилити и даже делает скриншоты страниц. При этом оценивается обычная и мобильная версия парсера. Поэтому мы не могли обойти стороной такой сервис и не сделать для него парсер. О том, что получилось - читайте по ссылке выше.
 Кастомный парсер Яндекс Картинок
Кастомный парсер Яндекс Картинок
На форуме неоднократно спрашивали когда в А-Парсер будет добавлен парсер картинок Яндекса. На данный момент такой парсер уже есть: SE::Yandex::Images. Но в данной статье будет показан пример кастомного парсера Яндекс.Картинок, который довольно хорошо демонстрирует возможности Net::HTTP. Подробности - по ссылке выше.
 Как получить полные ссылки из Baidu
Как получить полные ссылки из Baidu
Также довольно часто спрашивают как получить полные ссылки из Baidu. Дело в том, что этот поисковик обрезает ссылки в выдаче, и на выходе получаются ссылки такого вида:
Поэтому в данной статье будет показан способ получения полных ссылок с помощью A-Parser.
 Кроме этого:
Еще больше различных рецептов в нашем Каталоге примеров!
Кроме этого:
Еще больше различных рецептов в нашем Каталоге примеров!
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники:
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 28/09/16 в 07:10 |
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 13/10/16 в 14:00 |
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 25/10/16 в 07:58 |
|
|
|
|
| |
+
С нами с 23.07.07
Сообщения: 145
Рейтинг: 142
|
| Добавлено: 26/10/16 в 16:03 |
Инструмент отличный! Спасибо! 
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 07/11/16 в 13:01 |
Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
16-й выпуск Сборника рецептов. В нем мы научимся парсить OpenSiteExplorer с авторизацией, попробуем забирать все сайты из Яндекс.Каталога и сделаем парсер Яндекс.Новостей. Поехали!
Парсинг OpenSiteExplorer (MOZ) с авторизацией
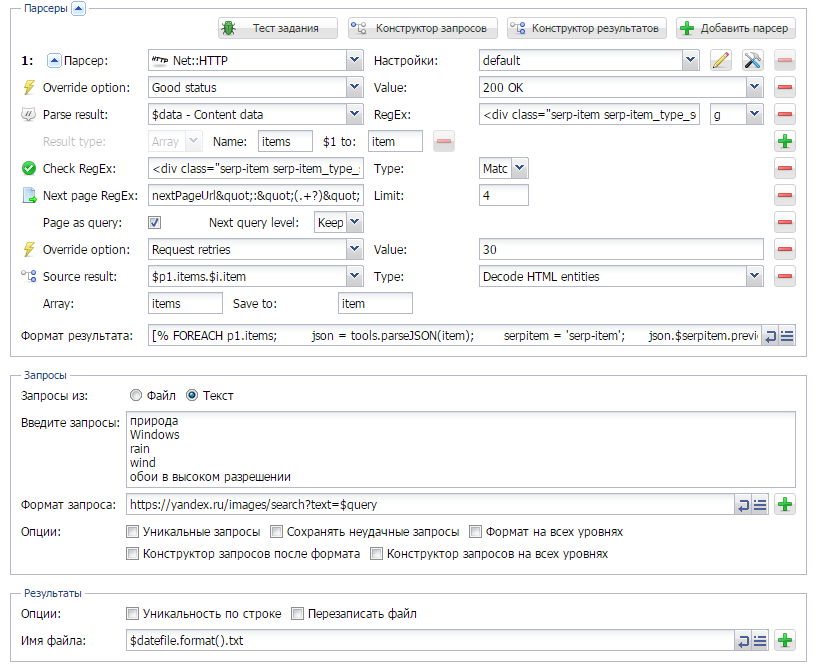
С помощью рассмотренного в статье способа, можно парсить OSE с авторизацией, что в свою очередь позволяет обходить ограничение на 10 запросов с одного IP в сутки. Плюс ко всему, значительно расширен набор возвращаемых параметров по сравнению со стандартным парсером. Кроме этого, можно совсем не использовать прокси, что дает значительный прирост в скорости! Сам пресет и описание - по ссылке выше.
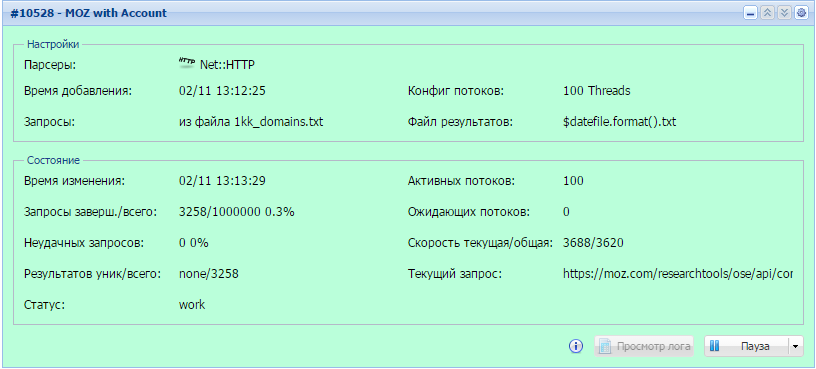 Парсинг всех сайтов из указанной категории Я.Каталога
Парсинг всех сайтов из указанной категории Я.Каталога
Многие пользователи A-Parser неоднократно спрашивали о возможности спарсить все сайты из Яндекс.Каталога. Поэтому мы публикуем сам пресет и подробное описание процесса его создания и работы. Все это - по ссылке выше.
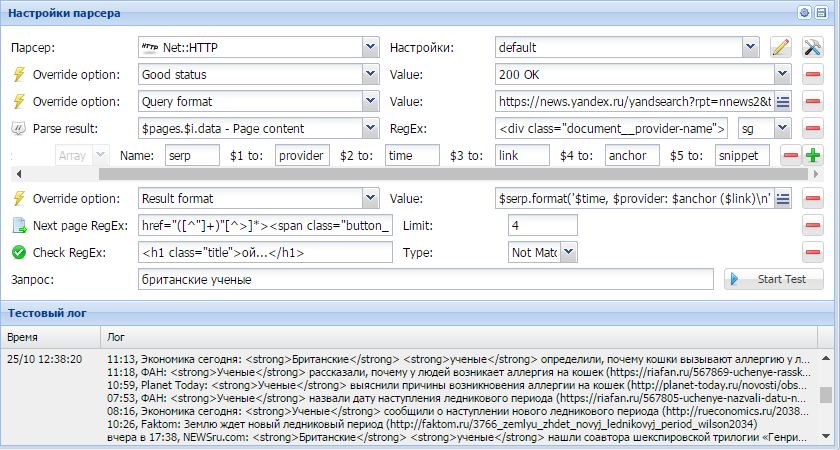
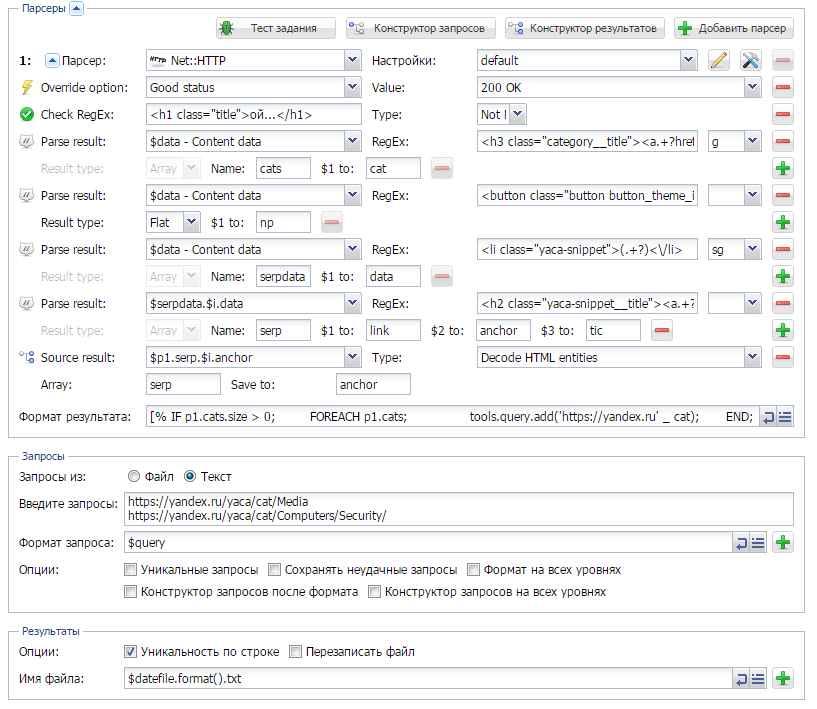 Как парсить Яндекс.Новости?
Как парсить Яндекс.Новости?
В А-Парсере в стандартном парсере Google можно парсить новости. А вот для Яндекса на данный момент нету такой возможности. Но решается это довольно просто. Как именно - читайте по ссылке выше. Плюс бонусом небольшой пресет для парсинга подсказок из Я.Новостей - еще один способ парсить ключевые слова
Кроме этого:
Еще больше различных рецептов в нашем Каталоге примеров!
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
|
|
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 15/11/16 в 07:38 |
A-Parser - 1.1.681 - обход защиты CloudFlare, улучшения в конструкторах запросов

В версии A-Parser 1.1.681 добавлен автоматический обход проверки CloudFlare на браузер, тем самым позволяя собирать информацию с сайтов под защитой самого популярного облачного провайдера. Работает в парсерах Net::HTTP, HTML::LinkExtractor и HTML::TextExtractor
В конструкторах запросов улучшена логика при разделении запроса на части
Исправления в связи с изменениями в выдачи
- SE::Yandex - пропускались некоторые ссылки
 SE::MailRu, SE::MailRu,  SE::Baidu SE::Baidu
Исправления
- Исправлена поддержка тега meta http-equiv в парсере Net::HTTP
- Теперь x64 Linux версия A-Parser запускается на всех современных дистрибутивах
- В парсере SE::Yandex::Direct::Frequency исправлена ошибка, которая могла приводить к зацикливанию запросов
- Исправлена ошибка в Тестировщике заданий, при которой не очищался результат предыщущего парсинга
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 01/12/16 в 13:13 |
Доброго времени суток, друзья!
Отныне в A-Parser добавлена уникальная возможность создавать свои парсеры на языке JavaScript:
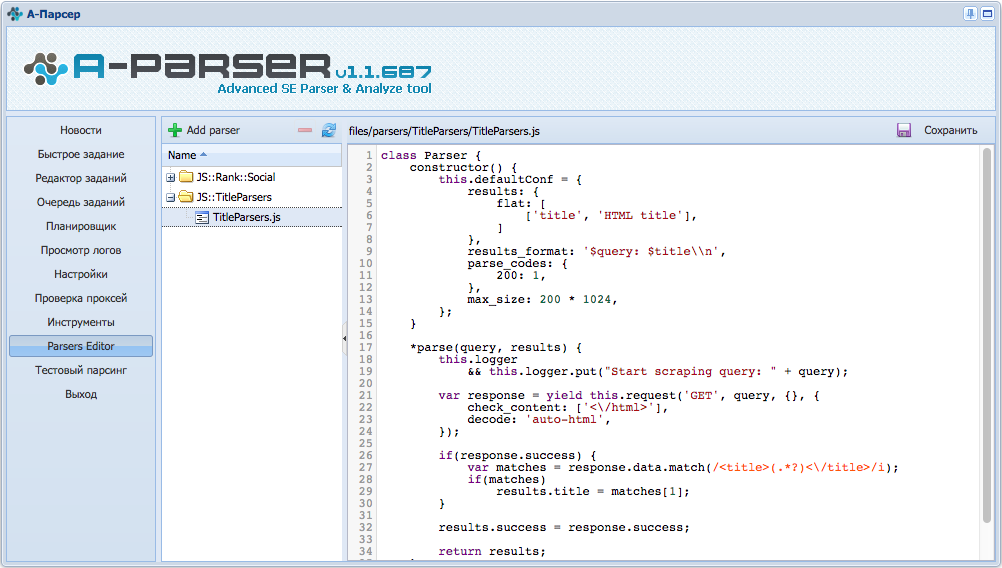
Давайте более подробно рассмотрим нововведения:
- теперь возможна реализация парсеров, регеров, постеров и т.п. любого уровня сложности, используя все преимущества A-Parser
- API будет дорабатываться и пополняться полезными возможностями
- для тех кто уже готов пользоваться новым функционалом - вступайте в наш чат https://join.skype.com/nMAYI9lpsJ9Z для JavaScript разработчиков
- ограничения: работает на windows или linux-x64, только для Pro и Enterprise лицензий
Мы ежедневно работаем над улучшениями и предоставляем вам только качественный продукт!
Благодарим вас за использование A-Parser
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
-1
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 12/12/16 в 12:34 |
Всем привет!
Друзья, рады сообщить что мы обновили Каталог примеров и добавили 32 примера и 1 видео.
Более подробно вы можете всё просмотреть здесь: https://a-parser.com/threads/1738/

Всем профитной недели и приятной работы в месте с A-Parser!
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
-1
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 16/12/16 в 15:43 |
Дорогие друзья!

Рады сообщить о том, что мы впервые запустили новогодний розыгрыш 3 лицензий A-Parser'а. Две "Lite" и одну "Pro". Подробнее об условиях и дате вы можете узнать в нашей группе Вконтакте: https://vk.cc/5YBNVX
Не упустите этот момент, возможно розыгрыш произойдёт только один раз
С любовью, команда A-Parser!
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
-1
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 27/12/16 в 12:30 |
1.1.712 - новогодняя юбилейная 100-ая версия, JavaScript парсеры
 Всех с наступающим новым годом!
Всех с наступающим новым годом! Участвуйте в конкурсе и получайте бесплатные лицензии, но об этом ниже
Сегодня я хочу вам представить юбилейную 100-ую версию A-Parser'a! Да, мы выпустили ровно [URL="https://a-parser.com/categories/13/"]100 версий[/URL] за почти 5 лет существования нашего парсера. Разработка парсера никогда не останавливается, сейчас он буквально пухнет от возможностей! Это хорошо подчеркивает все принципы и подходы заложенные в A-Parser еще в далеком 2012 году.
Одно из главных новшеств новой версии - JavaScript парсеры, теперь каждый кто обладает хотя бы минимальными знаниями программирования сможет создавать высокопроизводительные парсеры на языке JavaScript используя все возможности A-Parser'а(многопоточность, работу с прокси, шаблонизатор, обработка запросов и результатов, и многое другое)
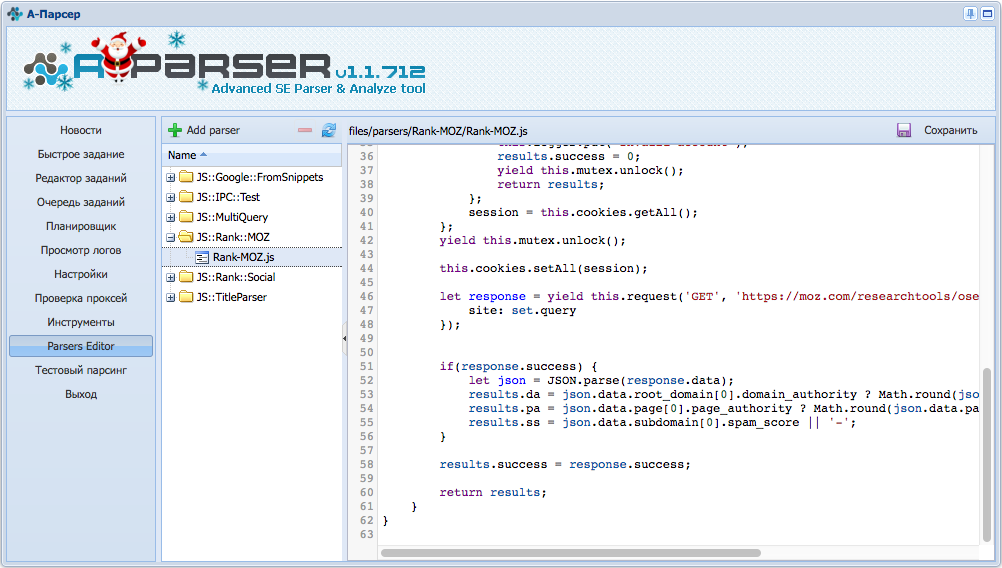 A-Parser
A-Parser давно перестал быть просто парсером, на сегодняшний день это полнофункциональная платформа для сбора информации в промышленных масштабах, которая позволит вам собирать информацию из самых разных источников и множеством разных способов. В следующем году вас ждет еще больше новых возможностей, следите за новостями!
Улучшения
- JavaScript парсеры - возможность создавать свои парсеры используя все преимущества A-Parser
- JS парсеры: возможность получить и установить Cookies
- JS парсеры: мютекс для синхронизации между потоками
- JS парсеры: возможность использования инструментов tools
- JS парсеры: поддержка запросов к другим парсерам
- Множественные оптимизации всех парсеров, обработке подвергаются только те элементы страницы которые необходимы в результатах парсинга
- В парсере
 HTML::TextExtractor будут игнорироваться блоки меню без текста HTML::TextExtractor будут игнорироваться блоки меню без текста
- В парсере
 SE::Google::Compromised добавлена возможность проверки подозрительных сайтов по всем страницам SE::Google::Compromised добавлена возможность проверки подозрительных сайтов по всем страницам
- API: добавлена возможность получить количество активных аккаунтов(для Яндекса)
- API: при выставленном флаге rawResults будут передаваться все доступные результаты
- Убрана настройка Raw data results, теперь необходимость этих результатов определяется автоматически
- Добавлена возможность работы с одним прокси сервером(параметр Reuse proxy beetwen retries)
- Если ошибка в шаблонизаторе произошла во время парсинга она будет записана в лог
Исправления в связи с изменениями в выдачи
- В парсере
 SE::YouTube не собиралась выдача SE::YouTube не собиралась выдача
- В парсере
 SE::Bing не парсилось количество результатов для новостей SE::Bing не парсилось количество результатов для новостей
- В парсере
 SE::Google не собирались рекламные блоки SE::Google не собирались рекламные блоки
- В парсере
 SE::Yandex некоторые позиции в выдаче могли пропускаться SE::Yandex некоторые позиции в выдаче могли пропускаться
- В парсере
 SE::Yandex::Register исправлена обработка ошибок регистрации SE::Yandex::Register исправлена обработка ошибок регистрации
Исправления
- Исправлена ошибка с обработкой запросов вне рабочего каталога A-Parser, что в некоторых случаях могло привести к проблемам с безопасностью
- В парсере
 SE::Yandex::WordStat в редких ситуациях могла зациклиться работа с одним прокси SE::Yandex::WordStat в редких ситуациях могла зациклиться работа с одним прокси
- В парсере
 Net::HTTP не корректно работала опция Check next page при редиректе на другой URL Net::HTTP не корректно работала опция Check next page при редиректе на другой URL
- Исправлена проблема с работой
 Net::DNS на ОС Linux x64 Net::DNS на ОС Linux x64
- Исправлен вывод ошибок в логе при уникализации "не доменов"
- Исправлена работа парсера
 HTML::TextExtractor::LangDetect HTML::TextExtractor::LangDetect
- Исправлен парсер
 Check::BackLink, ошибка появилась в предыдущей версии Check::BackLink, ошибка появилась в предыдущей версии
- Не выводились внешние переменные в методе .format, ошибка появилась в предыдущей версии
Напоминаем, что мы разыгрываем 3 лицензии на A-Parser общей стоимостью $437, участвуйте в конкурсе, победитель будет выбран 5ого января 2017!
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 332
Рейтинг: 37
|
| Добавлено: 05/01/17 в 12:44 |
Доброго времени суток друзья! Команда A-Parser поздравляет вас с наступившим 2017 годом и наступающим Рождеством.
Не забывайте о нашем розыгрыше https://vk.cc/5YBNVX/. Мы разыграем сегодня 3 лицензии на A-Parser общей стоимостью $437. Результаты розыгрыша после 17:00 по Москве. Более подробную информацию смотрите по ссылке которая указана выше.
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
Текстовая реклама в форме ответа
Заголовок и до четырех строчек текста
Длина текста до 350 символов
Купить рекламу в этом месте! |
|
Спонсор сайта


|





 SE::Google::position,
SE::Google::position,  SE::Yandex::position, ...) теперь поддерживают съем позиций сразу по нескольким доменам
SE::Yandex::position, ...) теперь поддерживают съем позиций сразу по нескольким доменам