С нами с 03.06.13
Сообщения: 309
Рейтинг: 37

|
 Добавлено: 15/12/17 в 13:40 Добавлено: 15/12/17 в 13:40 |
Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
В 20-м сборнике рецептов наш пользователь glukmaster поделится опытом решения реальной задачи на практике с помощью A-Parser. А также мы будем анализировать тексты и автоматизировать регистрацию аккаунтов Яндекса. Поехали!
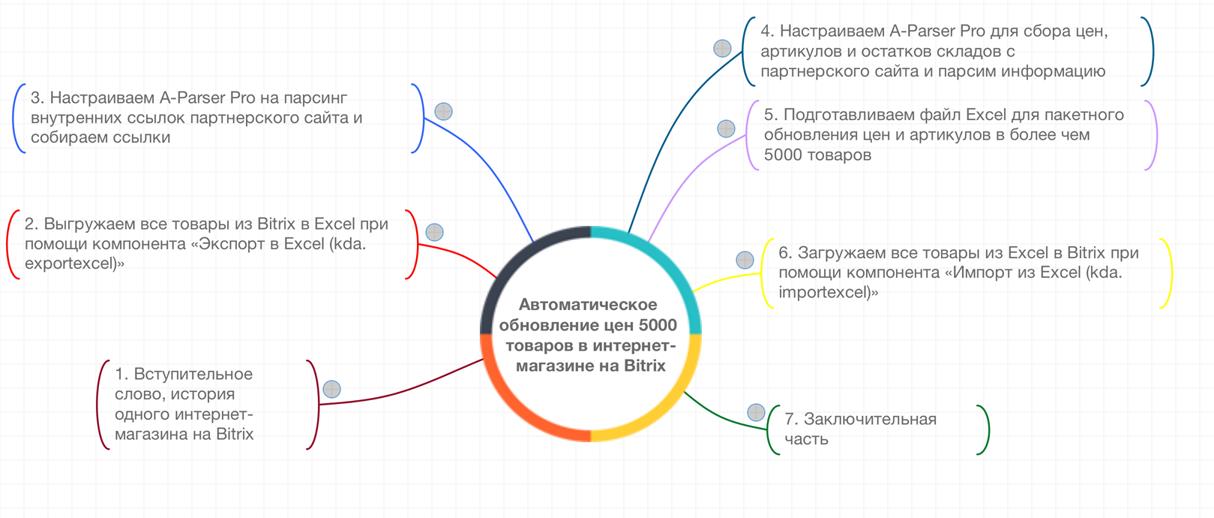
Автоматическое обновление цен 5000 товаров в интернет-магазине на Bitrix
Цикл видео из 7 частей, в которых очень детально и наглядно показано, как решать такую задачу, как обновление цен в интернет магазине. Для парсинга используется A-Parser. Посмотреть видео можно по ссылке выше.
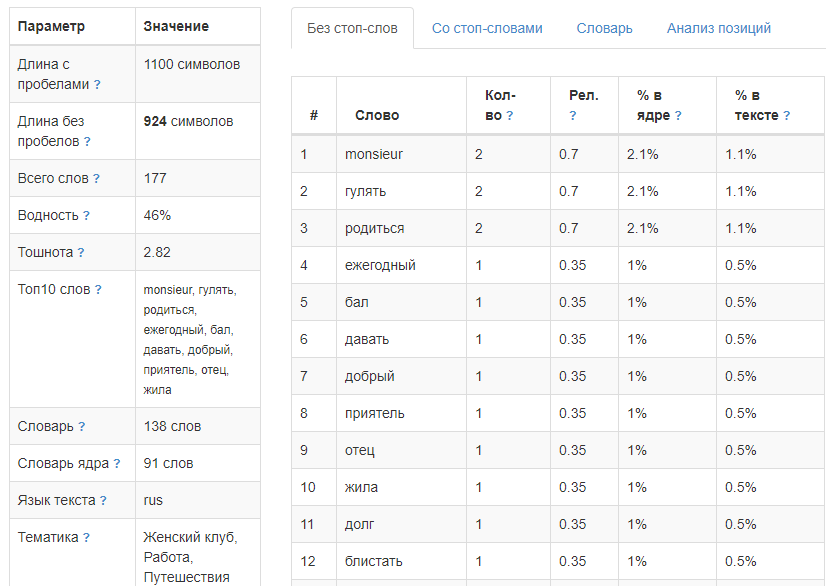
 Анализ текста
Анализ текста
Одним из самых популярных кейсов по применению А-Парсера является парсинг текстов. При этом возникает задача их анализа. Полноценно решить эту задачу позволяют специальные ресурсы. Ранее мы уже публиковали пресет по парсингу одного из таких сервисов. Теперь же это решение полностью переписано в виде JS-парсера, добавлена возможность анализировать не только тексты, а и полностью страницы, т.е. подавать на вход ссылки. Все детали и сам парсер - по ссылке выше.
 Автоматизация регистрации аккаунтов Яндекса
Автоматизация регистрации аккаунтов Яндекса
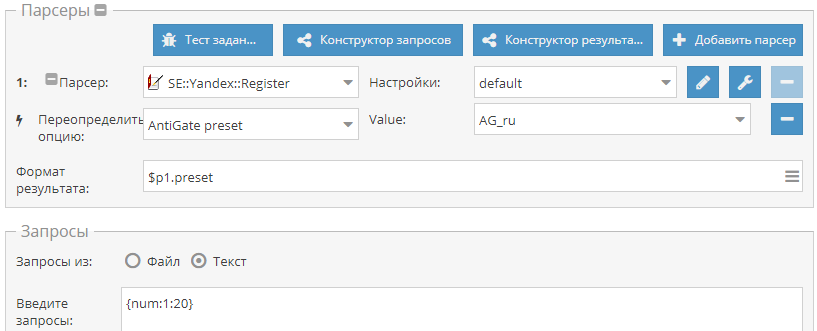
Как известно, для парсинга WordStat нужны аккаунты Яндекса. А-Парсер умеет их регистрировать, но их срок жизни невелик, т.к. спустя 1-2 суток включается проверка номера телефона. Поэтому возникает необходимость периодической регистрации новых аккаунтов. И это можно легко автоматизировать. По ссылке выше показано как это сделать.
 Кроме этого:
Еще больше различных рецептов в нашем обновленном Каталоге!
Кроме этого:
Еще больше различных рецептов в нашем обновленном Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники рецептов:
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
- Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
- Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
- Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
- Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
Сборники статей:
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 26/12/17 в 13:45 |
1.2.50 - улучшение стабильности, поддержка Xevil и множество исправлений в стандартных парсерах
 Улучшения
Улучшения
- Уменьшение потребления памяти и улучшение стабильности работы x64 версий
- Добавлена поддержка 2captcha и Xevil в
 Util::ReCaptcha2 Util::ReCaptcha2
- Добавлен Parse all results и Parse related to level для
 SE::Bing SE::Bing
- В SE::Bing добавлена возможность задавать Safe Search, а также добавлен повтор запроса при получении кешированной "короткой" выдачи
- В
 SE::Yandex::Translate, добавлен обход ограничения на кол-во символов в запросе, что позволяет переводить очень большие запросы (>10k символов) SE::Yandex::Translate, добавлен обход ограничения на кол-во символов в запросе, что позволяет переводить очень большие запросы (>10k символов)
- В
 SE::Google::Modern добавлена возможность задать автоматическое определение языка интерфейса в зависимости от IP SE::Google::Modern добавлена возможность задать автоматическое определение языка интерфейса в зависимости от IP
- Движок V8 обновлен до версии 6.4
Исправления в связи с изменениями в выдаче
Исправления
- Исправлена работа SE::Bing:
- устранена ситуация, когда выдавалась одинаковая выдача для всех страниц
- исправлена работа параметра Links per page
- исправлен парсинг количества результатов в некоторых ситуациях
- исправлена ошибка, при которой не было результатов, если в выдаче одна ссылка
- Исправлена работа с каптчей в
 SE::Yandex::Wordstat SE::Yandex::Wordstat
- Исправлена ошибка, когда при запросе с опечаткой SE::Google::Modern не забирал результаты с первой страницы
- Исправлена ошибка в
 Rank::MajesticSeo, при которой неправильно определялся бан IP Rank::MajesticSeo, при которой неправильно определялся бан IP
- В
 SE::Google::Trends исправлена работа при изменении формата результата по-умолчанию SE::Google::Trends исправлена работа при изменении формата результата по-умолчанию
- В SE::Google::Modern для Search from country изменен параметр: вместо cr теперь используется gl - это на данный момент позволяет более точно задавать регион
- Исправлена проблема с чрезмерным потреблением памяти в JavaScript парсерах
- Исправлена ошибка влияющая на стабильность работы на Linux и Windows
- Исправлена ошибка в
 SE::Yandex, при которой не было результатов, если в выдаче одна ссылка SE::Yandex, при которой не было результатов, если в выдаче одна ссылка
Команда A-Parser поздравляет всех с Новым годом и Рождеством! Спасибо что вы с нами!
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 10/01/18 в 10:40 |
Сборник статей #2: цикл статей-уроков по созданию JS парсеров
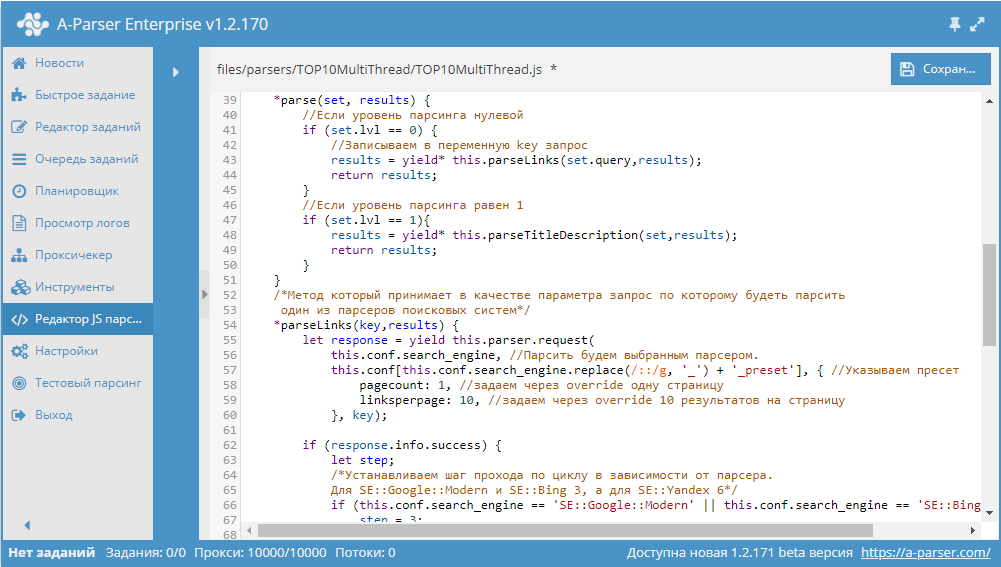
Как известно, в A-Parser есть возможность создавать свои собственные парсеры, которые могут иметь практически любую логику и в то же время позволяют пользоваться всеми преимуществами А-Парсера. Для написания таких парсеров используется язык JavaScript. В нашей документации подробно описаны все функции и методы, которые можно использовать при написании парсеров. А в сегодняшнем сборнике мы на практических примерах покажем наиболее часто применяемые функции. Поехали!
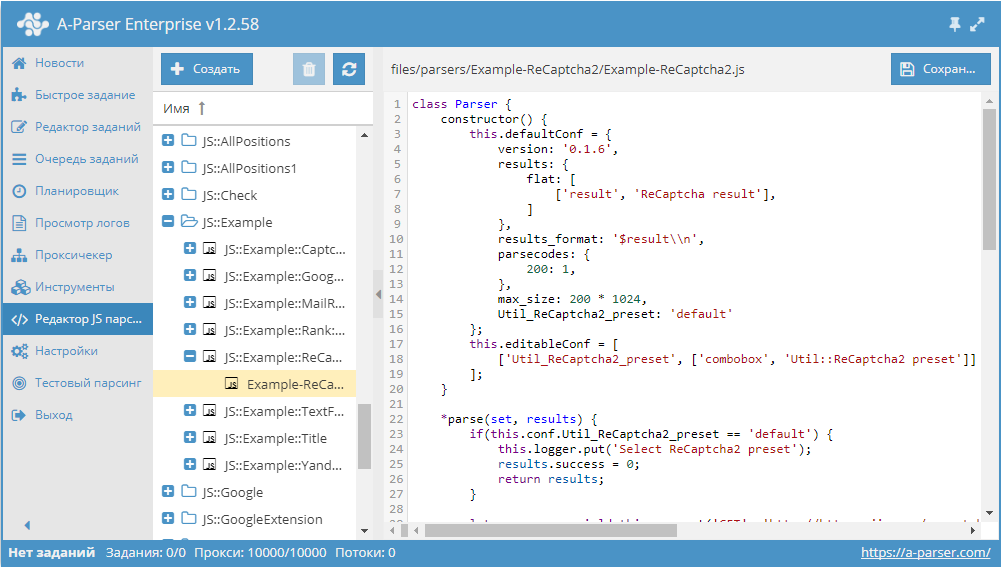
- Получение результатов от стандартного парсера.
В этой статье описано использование функции yield this.parser.request, которая позволяет работать с уже существующими парсерами, получать от них данные и дополнительно обрабатывать их.
- Парсинг сайта с проходом по страницах.
Здесь показан общий подход к созданию парсера, который будет "ходить" по страницам на сайте и забирать с них некоторую информацию.
- Парсинг title и description для топ10 сайтов по запросу.
В данном примере показано как написать собственный парсер, который объединит в себе две разных задачи: парсинг топ10 сайтов и парсинг данных из каждого полученного сайта. При этом также будет показана возможность реализации выбора между несколькими поисковиками, что делает такой парсер еще более универсальным.
- Реализация подстановки запросов и их многопоточной обработки.
Этот пример продемонстрирует, как "на лету" добавлять запросы с помощью tools.query.add, а также, как обрабатывать их в многопоточном режиме.
- Работа с CAPTCHA.
В этой статье на простом примере будет показан общий подход к работе с сайтами, на которых появляется каптча. Будет пошагово разобран алгоритм и продемонстрирован результат работы.
- Работа с ReCaptcha2.
А в этом примере по аналогии с обычной каптчей демонстрируется алгоритм работы с рекаптчей, а также вкратце поясняется принцип ее действия.
Для каждой статьи в конце будет продемонстрирован результат работы и дана ссылка на готовый парсер.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки  ) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники статей
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 23/01/18 в 16:50 |
1.2.78 - поддержка сессий в JS парсерах, улучшение SE::Google::Modern, правки в интерфейсе
 Улучшения
Улучшения
- Добавлена поддержка сессий в JavaScript парсерах
- В SE::Google::Modern добавлена поддержка сессий и улучшена производительность за счет уменьшения частоты появления каптч/рекаптч
- Добавлена переменная $query.prev - показывает запрос, который использовался на предыдущем уровне
- Для JS парсеров добавлен метод this.logger.putHTML, который позволяет вывести в лог HTML код
- В Lite версию добавленSE::Google::Modern и Util::ReCaptcha2
- В x86 версиях добавлено предложение перейти на x64
- Добавлена возможность переименовывания пресетов
- В окне выбора пресета для папок реализована "память на сворачивание"
- Изменены иконки для JS парсеров
- Исправлены ошибки с переводом в интерфейсе
- Исправлено отображение HTML тегов в логах
- Исправлен баг при импорте с вложенным парсером
- Исправлен баг с прокруткой при сохранении JS парсеров и пресетов
- Доработан Конструктор регулярных выражений
- Другие мелкие правки в интерфейсе, направленные на улучшение общей работы
Исправления в связи с изменениями в выдаче
Исправления
- Исправлен баг с перемещением заданий в очереди
- В SE::Google::Modern исправлен баг с кодировкой
- Исправлена работа параметров Request delay и Extra query string во всех JS парсерах
- Исправлен выбор файлов запросов
- Исправлено отображение иконок для JS парсеров
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 02/02/18 в 11:44 |
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 13/02/18 в 11:16 |
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 23/02/18 в 13:09 |
1.2.138 - поддержка Node.js модулей, обработка ReCaptcha2 во всех парсерах Google, парсер AliExpress

В A-Parser 1.2.138 добавлена эмуляция node версии 8.9.x с поддержкой загрузки модулей и частичной реализацией fs и net модулей. Это дает возможность обращаться из JavaScript парсеров напрямую к файловой системе, а также использовать подключение по TCP из модулей к другим сервисам(например mysql, redis, chrome...).
Все это позволило загружать и использовать node модули из каталога npm, в котором собраны множество полезных библиотек для обработки данных, коннекторы к базам данных и множество других интересных вещей. На данный момент протестированы следующие модули: md5, async-redis, jsdom, puppeter.
Улучшения
Исправления в связи с изменениями в выдаче
Исправления
- Исправлена работа Конструктора регулярных выражений
- Исправлена работа с кодировками в парсерах переводчиков и JS парсерах
- Исправлена работа
 SE::Google::Position SE::Google::Position
- Исправлен выбор региона в
 SE::Yandex:: Direct SE::Yandex:: Direct
- Исправлена работа опции Location в SE::Google::Modern
- Исправлена работа сессий в SE::Google::Modern при переопределенном домене
- Исправлена ошибка при совместном использовании опций Перезаписи файла, Начального и Конечного текстов
- Исправлено отображение вкладок в Тесте задания
- Исправлено отображение списка пресетов в поле Запустить по завершению
- Исправлена работа this.proxy.set в JS парсерах
- Исправлена передача дополнительных параметров в JS парсерах
- Исправлена ошибка, из-за которой через API нельзя было указать Начальный и Конечный тексты
- Исправлен экспорт пресетов
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 05/03/18 в 13:13 |
Использование Xevil совместно A-Parser для разгадывания ReCaptcha2

Как известно, сейчас Google при парсинге очень часто выдает рекаптчу, что значительно усложняет и замедляет сбор данных.
В A-Parser есть возможность обходить данную проблему, разгадывая рекаптчу с помощью сторонних сервисов. Поддерживаются различные онлайн сервисы, а также программные решения.
Одним из таких решений есть XEvil. Его использование дает хороший прирост в скорости, а также значительно удешевляет парсинг, ведь здесь нету оплаты за количество разгаданных каптч/рекаптч, как в онлайн сервисах. Кроме этого, XEvil умеет разгадывать практически любые обычные каптчи (в виде картинки) и данная возможность также поддерживается в A-Parser.
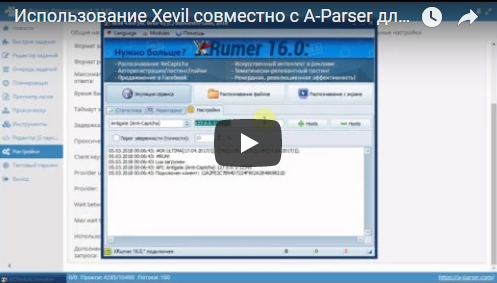
На данный момент использовать разгадывание рекаптчи с помощью XEvil можно в таких парсерах:
В видео показано:
- подключение Xevil к A-Parser для работы с ReCaptcha2
- проверка работы и демонстрация работы в SE::Google::Modern
Ознакомиться более детально с возможностями XEvil можно по ссылкам:
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
1
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 15/03/18 в 10:41 |
Сборник рецептов #21: уведомления в Telegram из A-Parser, мультифильтр и парсинг IMDb
21-й сборник рецептов. В нем мы научимся отправлять сообщения в Telegram прямо из A-Parser, изучим работу с модулями Node.js в JS парсерах на примере решения задачи фильтрации по множеству признаков, а также спарсим весь IMDb. Поехали!
Уведомления в Telegram из A-Parser
Telegram является одним из самых популярных мессенджеров благодаря своей простоте, и в то же время большому функционалу. Среди прочего, в Телеграме можно создавать ботов, с помощью которых можно делать чаты более интерактивными. Взаимодействие с ботом на на стороне сервера происходит через Telegram Bot API. Используя эти возможности, можно легко и буквально за несколько минут настроить уведомления себе в Telegram прямо из парсера. О том, как это сделать, а также несколько реальных примеров - по ссылке выше.

 Фильтрация по множеству признаков
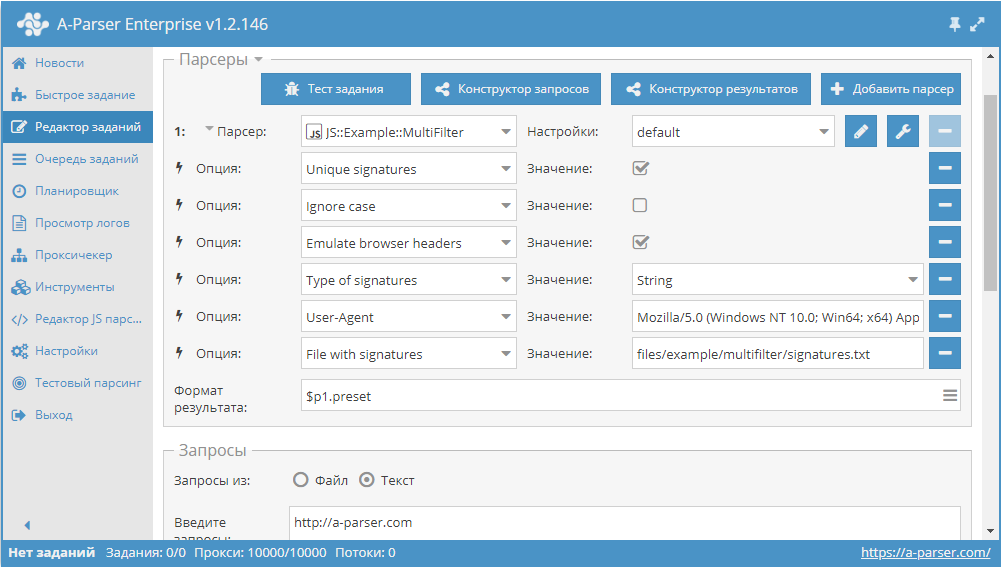
Фильтрация по множеству признаков
Как известно, для фильтрации в А-Парсере используется встроенный функционал фильтров. Но бывают ситуации, когда список признаков, наличие которых нужно проверять, очень большой и его сложно вписать в строку стандартного фильтра.
Начиная с версии 1.2.127 в A-Parser добавлена поддержка модулей Node.js. Благодаря этому появилась возможность читать список признаков из файла и использовать его для проверки страниц. О том, как это сделать, а также готовый парсер с мультифильтром - по ссылке выше.
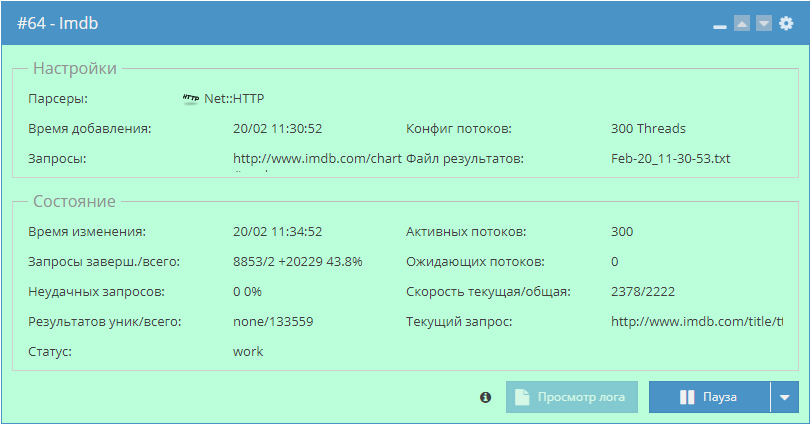
 Парсинг рекомендаций фильмов из IMDb
Парсинг рекомендаций фильмов из IMDb
Пример решения задачи по сбору данных о фильмах и их рекомендаций на IMDb. Данная статья показывает, как можно решать задачи, которые на первый взгляд требуют много времени и ресурсов, буквально за несколько часов. Узнать о том, как спарсить весь IMDb за 1,5 часа, а также посмотреть пресет и забрать готовую базу можно по ссылке выше.
 Еще больше различных рецептов в нашем обновленном Каталоге!
Еще больше различных рецептов в нашем обновленном Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
- Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
- Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
- Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
- Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
- Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
Сборники статей:
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 26/03/18 в 13:05 |
1.2.160 - поддержка SQLite, проверка доменов на клей, Parse all results в SE::Yahoo
 Улучшения
Улучшения
- Добавлена поддержка SQLite в JavaScript парсерах и шаблонизаторе, пример использования здесь
- Добавлена защита от случайного закрытия окна парсера
- В
 SE::Yahoo добавлены Parse all results и Parse related to level SE::Yahoo добавлены Parse all results и Parse related to level
 SE::Yandex::TIC полностью переписан, добавлена возможность проверять домены на клей SE::Yandex::TIC полностью переписан, добавлена возможность проверять домены на клей
- В
 Rank::MegaIndex добавлена поддержка ReCaptcha2 Rank::MegaIndex добавлена поддержка ReCaptcha2
- Улучшен парсинг сниппетов в
 SE:: DuckDuckGo SE:: DuckDuckGo
- Улучшен сбор почт в
 HTML::EmailExtractor HTML::EmailExtractor
Исправления в связи с изменениями в выдаче
Исправления
- Исправлена работа SE::Google::Modern на IPv6 прокси
- Исправлена ошибка, из-за которой SE::Google::Modern собирал ссылки с пометкой опасных сайтов в общий массив ссылок
- Исправлена работа с оператором поиска + в SE::Bing
- Исправлен парсинг запросов со спецсимволами в SE:: DuckDuckGo
- Исправлена работа Rank::MajesticSEO
- Исправлен баг с overrideOpts в JS парсерах
- Исправлена работа с переменными при их создании в Parse custom results, а также при использовании нижнего подчеркивания в именах в Конструкторе результатов
- Исправлена работа tools.js, баг появился в одной из предыдущих версий
- Исправлен баг, из-за которого А-Парсер падал на некоторых ОС, появился в одной из предыдущих версий
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 05/04/18 в 11:25 |
Видео урок: Создание JS парсеров. Работа с CAPTCHA
Третье видео в цикле уроков по созданию JavaScript парсеров. Здесь рассказано о том, как написать JS парсер, в котором будет поддержка антигейта для разгадывания каптч на страницах.
 В уроке рассмотрено:
В уроке рассмотрено:
- Создание JS-парсера для разгадывания капчи
- Работа с объектом this.captcha внутри JavaScript кода
- Описание процесса разгадывания каптчи, реализованного в A-Parser
Статья и готовый парсер: https://a-parser.com/resources/257/
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 16/04/18 в 12:45 |
Сборник рецептов #22: проверка индексации в нескольких ПС, многоуровневый парсинг и поиск сабдоменов
22-й сборник рецептов. В нем мы разберемся, как проверять индексацию всех страниц сайта одновременно в нескольких поисковиках, научимся парсить данные по ссылкам из выдачи одним заданием и будем искать сабдомены на сайтах. Поехали!
Получение страниц сайта и проверка индексации в Google и Яндекс
Данный пресет позволяет спарсить ссылки на все страницы сайта и одновременно проверить их на предмет индексации поисковиками (в примере Google и Яндекс, можно по аналогии добавить другие ПС). Готовый пресет и описание по ссылке выше.
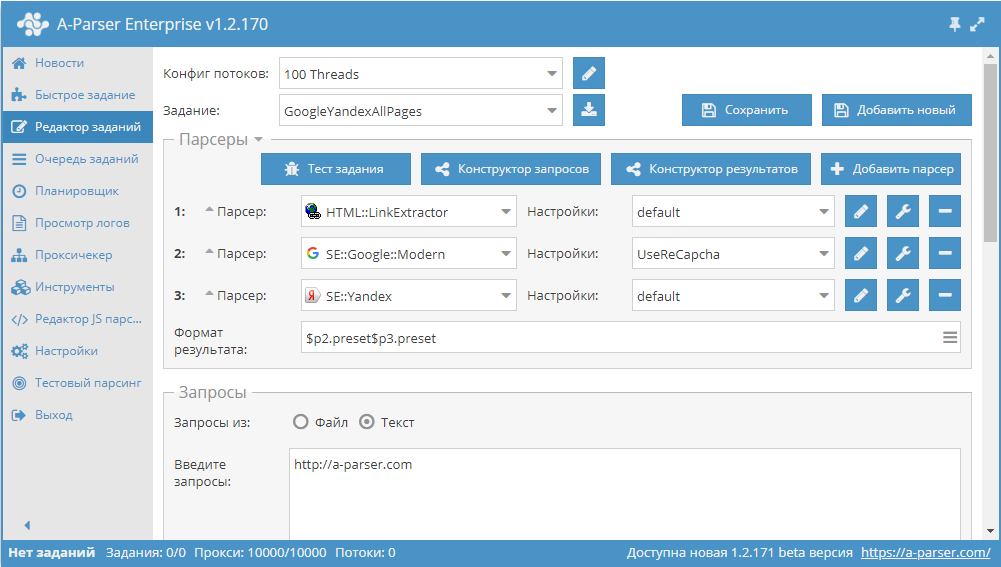 Парсим title и description для TOP10 поисковой выдачи по ключевому слову
Парсим title и description для TOP10 поисковой выдачи по ключевому слову
Пример использования tools.query.add в JavaScript парсерах. Данный парсер получает ссылки из выдачи, после чего собирает из каждой страницы title и description. И все это одним заданием с максимальной производительностью, благодаря многопоточному парсингу. Парсер с описанием доступны по ссылке выше.
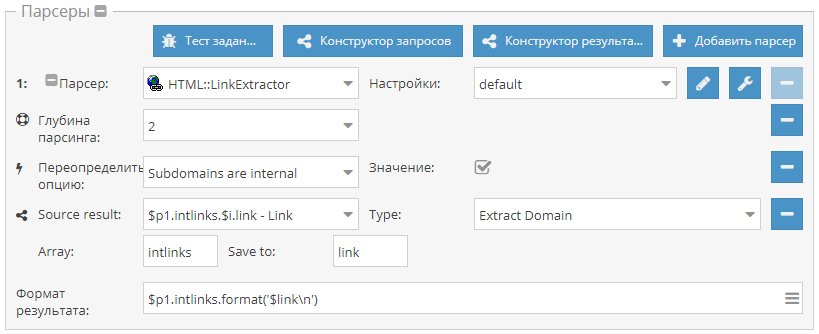
 Поиск сабдоменов сайта
Поиск сабдоменов сайта
Небольшой пример, который демонстрирует, как собрать поддомены одного или нескольких сайтов. Используется  HTML::LinkExtractor HTML::LinkExtractor и Parse to level для прохода вглубь по страницам сайта. При этом Конструктором результатов извлекаются из внутренних ссылок домены и выводятся с уникализацией по строке. Готовый пресет - по ссылке выше.
 Кроме этого:
Еще больше различных рецептов в нашем обновленном Каталоге!
Кроме этого:
Еще больше различных рецептов в нашем обновленном Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
- Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
- Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
- Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
- Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
- Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
- Сборник рецептов #21: уведомления в Telegram из A-Parser, мультифильтр и парсинг IMDb
Сборники статей:
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
1
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 26/04/18 в 11:40 |
Сборник статей #3: пагинация, переменные и БД SQLite
В этом сборнике статей мы рассмотрим все возможные варианты решения задачи прохода по пагинации на сайтах, очень детально изучим работу с переменными в JavaScript парсерах, а также попробуем работать с базами данных SQLite на примере парсера курсов валют. Поехали!
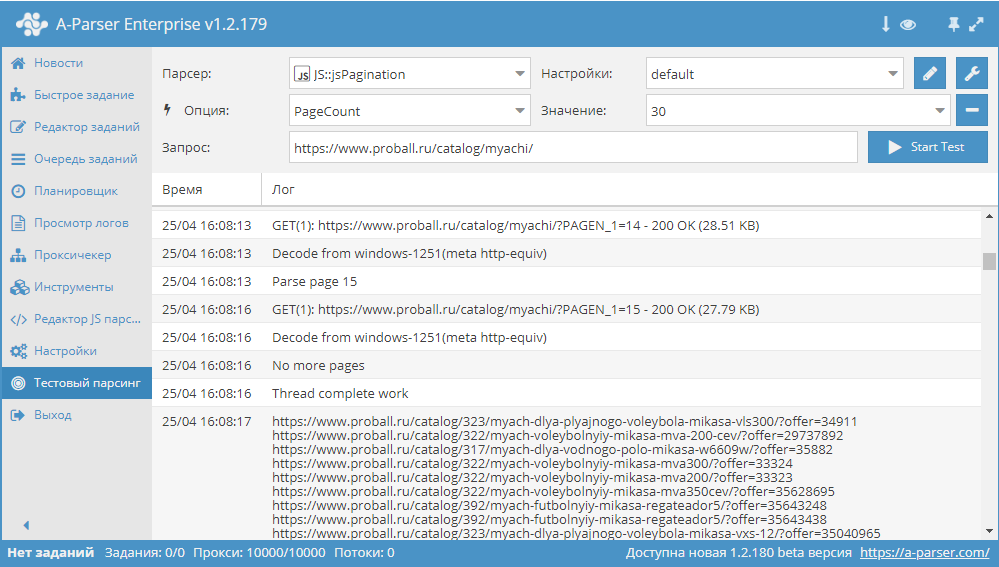
Обзор вариантов прохода по пагинации
В A-Parser существует несколько способов, с помощью которых можно реализовать проход по пагинации. В связи с их разнообразием, становится актуальным вопрос выбора нужного алгоритма, который позволит максимально эффективно переходить по страницам в процессе парсинга. В этой статье мы постараемся разобраться с каждым из способов максимально подробно. Также будут показаны реальные примеры и даны рекомендации по оптимизации многостраничного парсинга. Статья - по ссылке выше.
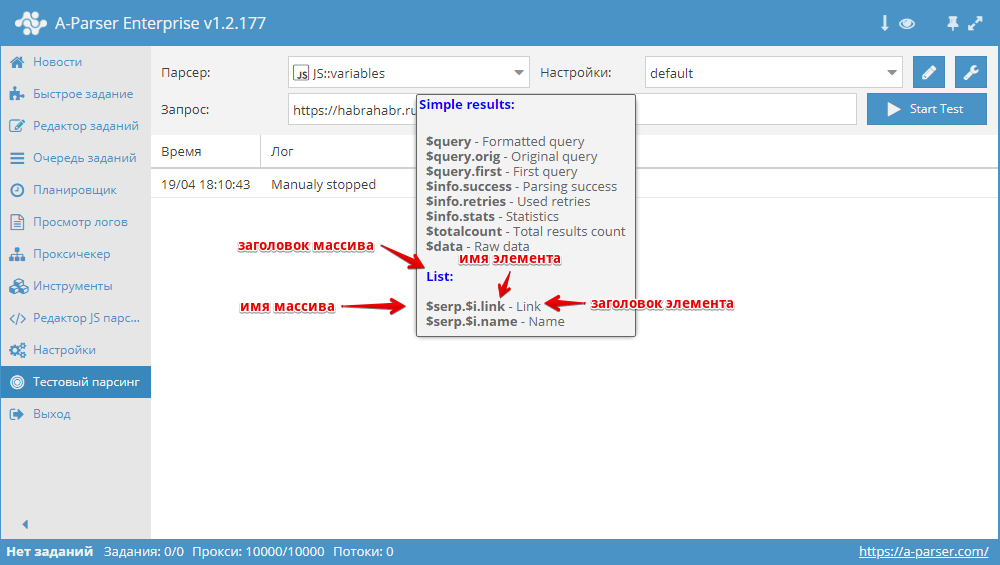
 Переменные в парсерах JavaScript
Переменные в парсерах JavaScript
JS парсеры в А-Парсере появились уже около года назад. Благодаря им стало возможным решать очень сложные задачи по парсингу, реализовывая практически любую логику. В этой статье мы максимально подробно изучим работу с разными типами переменных, а также узнаем, как можно оптимизировать работу сложных парсеров. Все это - в статье по ссылке выше.
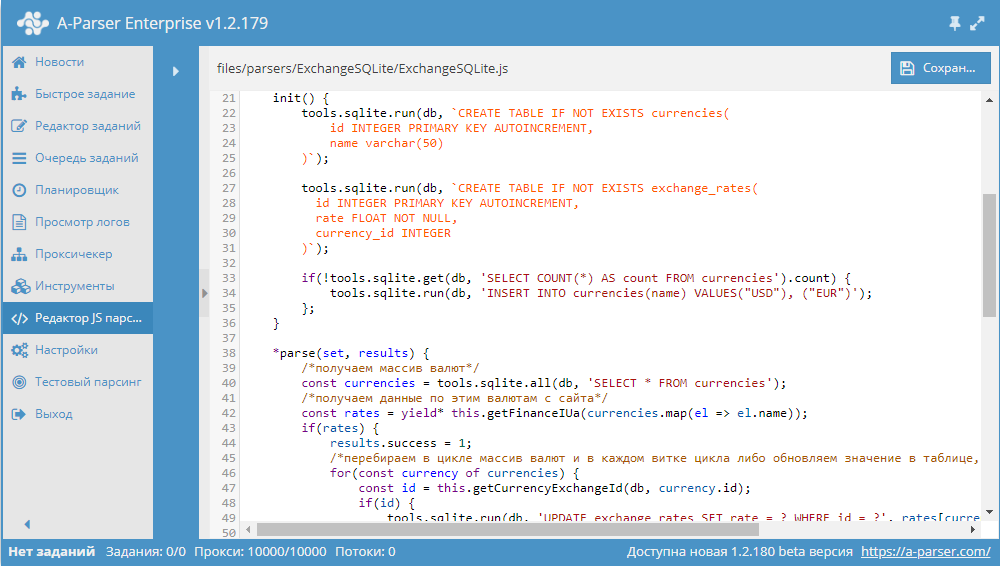
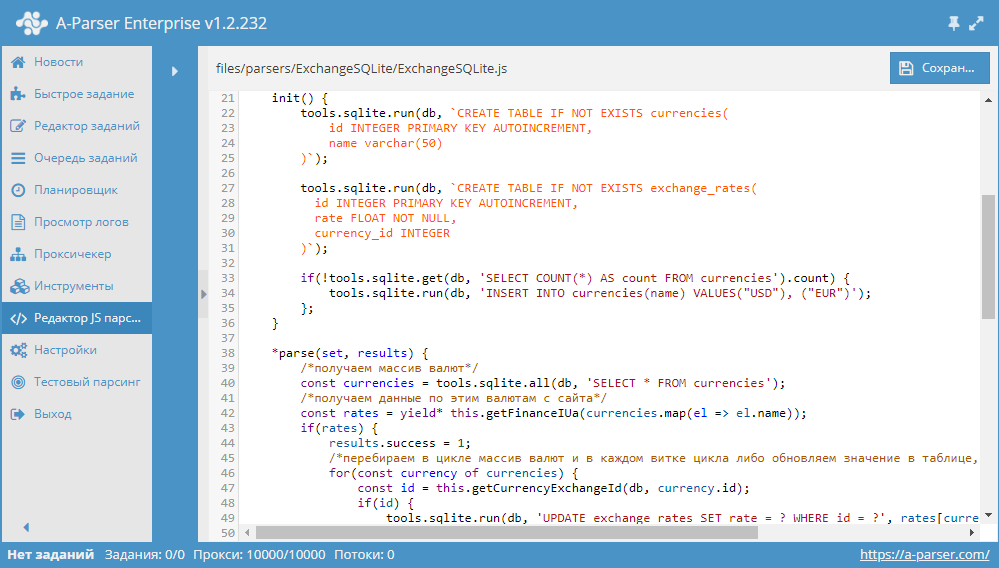
 Разработка JS парсера с сохранением результата в SQLite
Разработка JS парсера с сохранением результата в SQLite
Начиная с версии 1.2.152 в A-Parser появилась возможность работать с БД SQLite.
В данной статье мы рассмотрим разработку JavaScript парсера, который будет парсить курсы валют из сайта finance.i.ua и сохранять их в БД. В результате получится парсер, в котором продемонстрированы основные операции с базами данных. Подробности, а также готовый парсер - по ссылке выше.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки ) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники статей
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 07/05/18 в 12:40 |
1.2.185 - увеличение скорости в SE::Google::Modern, новые возможности Net:: DNS, множество улучшений

Улучшения
- SE::Google::Modern - многократно увеличена скорость парсинга
- Множество улучшений в
 Net:: DNS: Net:: DNS:
- Возможность указать несколько DNS и задать метод выбора
- Бан нерабочих/плохих DNS по специальному эвристическому алгоритму
- Возможность вывести в результат использованный DNS сервер при удачном запросе
- В SE::Google::Modern добавлена опция Use sessions
- В SE::Yandex::WordStat добавлена настройка пресета антигейта для логина
- Также в SE::Yandex::WordStat удалены настройки Use logins/Use sessions, теперь они включены всегда
- Добавлена возможность автоматического удаления задания из Завершенных
- В макросе подстановок {num} добавлена поддержка обратного отсчета
- В JavaScript парсерах добавлена возможность сохранения произвольных данных в сессии
- В JavaScript парсерах добавлена возможность прямого сохранения в файл
- В API методе oneRequest/bulkRequest добавлена возможность указать configPreset
- В связи с неактуальностью удалены парсеры SE::Google::Mobile и SE::Yandex::Catalog
Исправления в связи с изменениями в выдаче
Исправления
- Количество неудачных больше не обнуляется при постановке на паузу
- Исправлена проблема с подключением Node.js модулей на Linux
- Исправлено падение парсера в редких ситуациях при использовании JS парсеров
- Решена проблема с подключением Node.js модулей lodash, sequelize
- Исправлена ошибка итератора при равных границах в макросе {num}
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 17/05/18 в 11:01 |
Разгадывание рекаптч в JS парсере
Очередное видео в цикле уроков по созданию JavaScript парсеров. Здесь показано, как реализовать разгадывание рекаптч в JS парсере.
 В уроке рассмотрено:
В уроке рассмотрено:
- Описание и настройка парсера Util::ReCaptcha2
- Описание принципа работы ReCaptcha2
- Создание кастомного JavaScript парсера с поддержкой разгадывания рекаптч
Ссылки:
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 28/05/18 в 12:45 |
Сборник рецептов #23: категории сайтов, парсинг в YML и преобразование дат
23-й сборник рецептов. В нем мы будем парсить категории сайтов из Google, научимся формировать файлы YML, а также разберемся, как парсить даты и преобразовывать их в единый формат. Поехали!
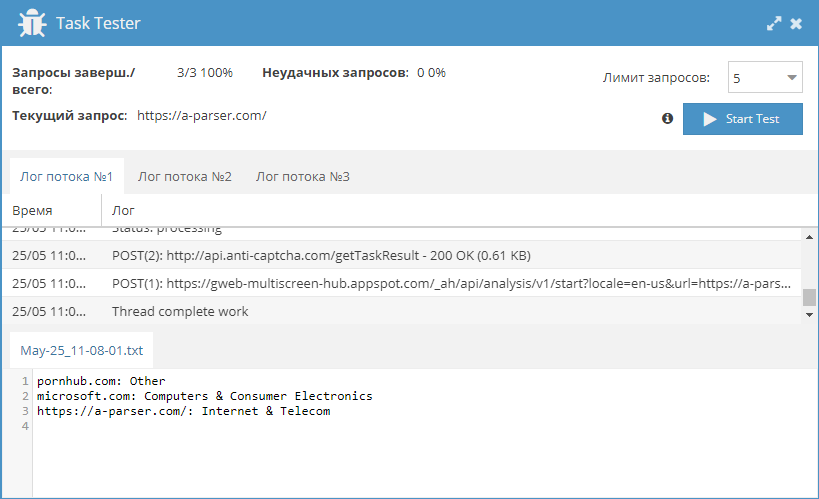
Получение категорий сайтов из Google
Категоризация сайтов - довольно актуальная задача, но существует немного сервисов, которые могут ее решить. Поэтому, по ссылке выше можно взять небольшой парсер, который позволяет получать категории сайтов из Google.
 Выгрузка товаров в формате YML
Выгрузка товаров в формате YML
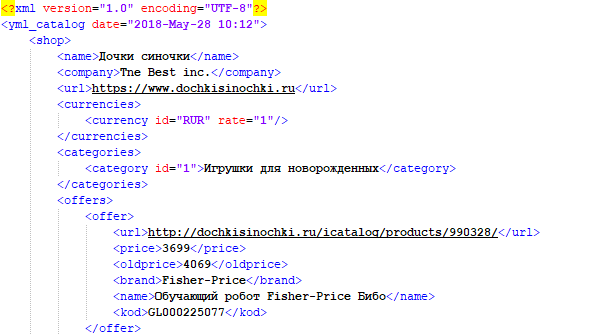
YML - это стандарт, разработанный Яндексом для работы с Маркетом. По своей сути, это файлы, схожие с XML, в которых содержится информация о товарах в интернет-магазине. Данный формат обеспечивает регулярное автоматическое обновление каталога на Яндекс.Маркет и позволяет отражать все актуальные изменения (наличие, цена, появление новых товаров). Пример парсинга интернет-магазина и сохранения собранных данных в YML можно посмотреть по ссылке выше.
 Парсим Google новости с датой и преобразуем ее
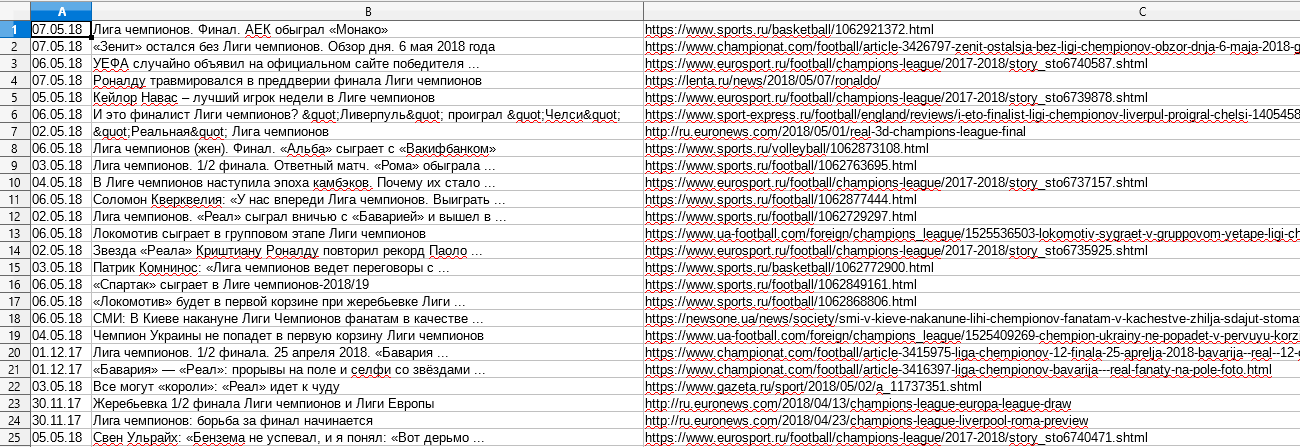
Парсим Google новости с датой и преобразуем ее
В поисковой выдаче Google возле новостей публикуется дата. Как правило, это могут быть метки " 10 ч. назад" или " 26 мая 2018 г.". Иногда может возникнуть задача спарсить все даты и привести их к единому виду. Как именно это сделать, можно узнать по ссылке выше.
 Кроме этого:
Еще больше различных рецептов в нашем Каталоге!
Кроме этого:
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники рецептов:
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
- Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
- Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
- Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
- Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
- Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
- Сборник рецептов #21: уведомления в Telegram из A-Parser, мультифильтр и парсинг IMDb
- Сборник рецептов #22: проверка индексации в нескольких ПС, многоуровневый парсинг и поиск сабдоменов
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 11/06/18 в 11:08 |
1.2.216 - улучшения в SE::Google::Modern и JS парсерах, а также множество других
 Улучшения
Улучшения
- Зависимая задача в Цепочке заданий теперь запускается только когда файл результатов не пустой
- Добавлен повтор без смены прокси при неудачной отправке рекаптчи в SE::Google::Modern
- Добавлен бан прокси при получении 403 кода ответа в SE::Google::Modern
- Процент неудачных запросов теперь отображается относительно числа выполненных запросов
- Добавлена возможность вызвать URL после выполнения задания
- Улучшен обзор каталогов при выборе файлов запросов
- Добавлена поддержка setInterval в JavaScript парсерах
- Уменьшено Wait between get status и улучшено логгирование в Util::ReCaptcha2
- Улучшена обработка редиректов
- Добавлена защита от бесконечного выполнения в JavaScript парсерах
- Значительно увеличены возможности check_content в JS парсерах
- В ответе API метода info добавлены параметры workingTasks, activeThreads, activeProxyCheckerThreads
Исправления в связи с изменениями в выдаче
Исправления
- Исправлено ведение лога при нескольких паузах задания
- Исправлена ошибка, из-за которой запрос считался неудачным при пустой выдаче в SE::Google::Modern
- Исправлена работа с url, содержащими фрагмент # в
 Net::HTTP Net::HTTP
- Исправлен парсинг ссылок в HTML::LinkExtractor
- Исправлена работа опции Pages count в SE::Yandex
- Исправлен выбор файлов запросов на Windows 10
- Исправлена ошибка, из-за которой иногда нельзя было удалить файл с запросами
- Исправлено отображение проксичекера в конфиге потоков
- Исправлена кодировка некоторых результатов в
 SE::Google::Suggest SE::Google::Suggest
- Исправлена ситуация, когда не читались настройки из config.txt
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 21/06/18 в 11:18 |
Сборник рецептов #24: уведомление в Telegram об экспайре доменов, чекер РКН и работа с SQLite
24-й сборник рецептов. В нем мы научимся мониторить окончание срока регистрации доменов с уведомлением в Телеграм, сделаем альтернативный чекер сайтов в базе РКН, а также на простом примере парсера курсов валют изучим работу с базами данных. Поехали!
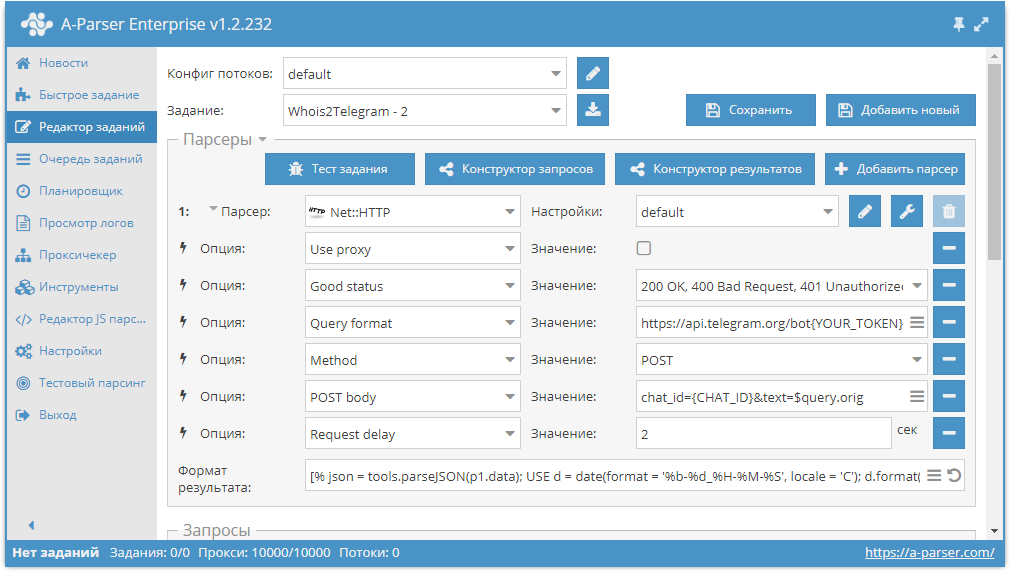
Получаем уведомления в Telegram об окончании срока регистрации доменов
Мониторинг сроков регистрации доменов - это довольно распространенная задача. A-Parser позволяет легко автоматизировать этот процесс. Более того, можно настроить получение прямо в Телеграм уведомлений о доменах, срок регистрации которых скоро закончится. Готовое решение для автоматической проверки с уведомлением - по ссылке выше.
 Проверка блокировки РосКомНадзора через GitHub
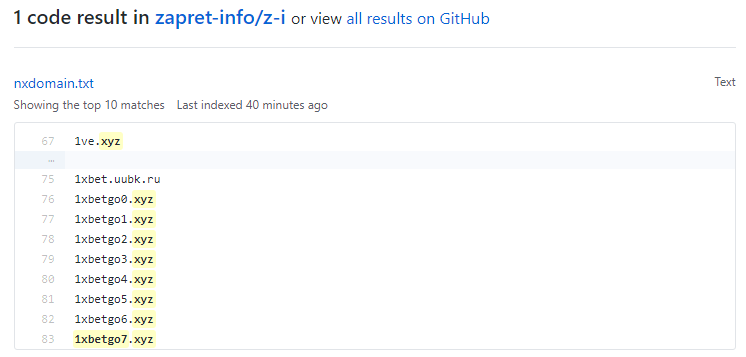
Проверка блокировки РосКомНадзора через GitHub
В А-Парсере есть стандартный парсер Check::RosKomNadzor Check::RosKomNadzor, который позволяет проверять наличие сайтов в базе РКН. Данные получаются напрямую из официального сервиса, для работы обязательно нужно подключать антигейт. Кроме того, официальный сервис РКН часто подвергается атакам, в связи с чем может быть недоступен. Но существуют альтернативные источники данных, доступность которых значительно выше и к тому же не требующие проверки в виде каптчи. Парсинг одного из таких источников и реализована в пресете по ссылке выше.
 Простой парсер обменника с записью в БД SQLite
Простой парсер обменника с записью в БД SQLite
Как известно, в A-Parser реализована возможность чтения/записи данных в БД SQLite. В этом рецепте показано использование этого функционала на примере парсинга курсов валют. Готовый парсер доступен по ссылке выше.
 Еще больше различных рецептов в нашем Каталоге!
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
- Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
- Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
- Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
- Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
- Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
- Сборник рецептов #21: уведомления в Telegram из A-Parser, мультифильтр и парсинг IMDb
- Сборник рецептов #22: проверка индексации в нескольких ПС, многоуровневый парсинг и поиск сабдоменов
- Сборник рецептов #23: категории сайтов, парсинг в YML и преобразование дат
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 02/07/18 в 12:03 |
1.2.246 - обновление базы Rank::CMS и новые функции в парсерах Baidu и MajesticSEO
 Улучшения
Улучшения
- В
 Rank::CMS обновлена база определяемых движков, теперь поддерживается одновременно старый и новый формат apps.json (при обновлении рекомендуется также обновить apps.json) Rank::CMS обновлена база определяемых движков, теперь поддерживается одновременно старый и новый формат apps.json (при обновлении рекомендуется также обновить apps.json)
 SE::Baidu полностью переписан: SE::Baidu полностью переписан:
- добавлен парсинг related keywords
- убран $cachedate из $serp, т.к. его похоже больше нет в выдаче
- добавлена опция Get full link, преобразующая обрезанные ссылки в полные
- исправлены некоторые регулярные выражения и баг с двойным http в ссылках
- Изменения в Rank::MajesticSEO:
- Добавлен параметр Check type, позволяет выбрать тип проверки: Root Domain/Subdomin/URL
- Убран параметр Extract domain
- Исправлена работа в некоторых случаях
- Улучшена отзывчивость в редакторе JavaScript парсеров
- Улучшена работа HTML::EmailExtractor, устранены зависания, которые возникали на определенных страницах
- Обновлен список регионов в парсерах Яндекс
- Пустой результат в SE::Google::Trends больше не считается неудачным запросом
- Улучшена работа с сессиями в SE::Yandex::WordStat
Исправления в связи с изменениями в выдаче
Исправления
- Исправлена ошибка, из-за которой процент обработанных запросов мог быть больше 100
- Исправлены ошибки, из-за которых парсинг мог зависать при снятии с паузы, а также сбивался перебор в макросах подстановок
- Исправлено отображение кириллицы в $headers в Net::HTTP
- Исправлена ошибка в Конструкторе результатов, из-за которой в редких случаях парсер мог падать
- Устранена проблема с кодировкой при работе с SQLite
- Исправлена ошибка со сменой прокси в JavaScript парсерах
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 12/07/18 в 11:30 |
Сборник статей #4: добавление товаров в OpenCart и парсинг JSON
В 4-м сборнике статей будет рассмотрено добавление товаров в OpenCart, а также описано создание универсального парсера JSON. В каждой статье приложены готовые JS парсеры, используя которые, можно на реальных примерах изучить описанные методы и поэксперементировать с ними. Поехали!
Работаем с OpenCart. Часть 1. Вступление.
Данная статья начинает цикл об одной из наиболее часто запрашиваемых возможностей - заливке товаров в интернет-магазин. A-Parser - это универсальный инструмент, который кроме прочего может решать и такие задачи. Для тестов выбран движок OpenCart, в 1-й статье будет рассмотрена авторизация, получение списка товаров и добавление товара. Подробности, а также пример парсера - по ссылке выше.
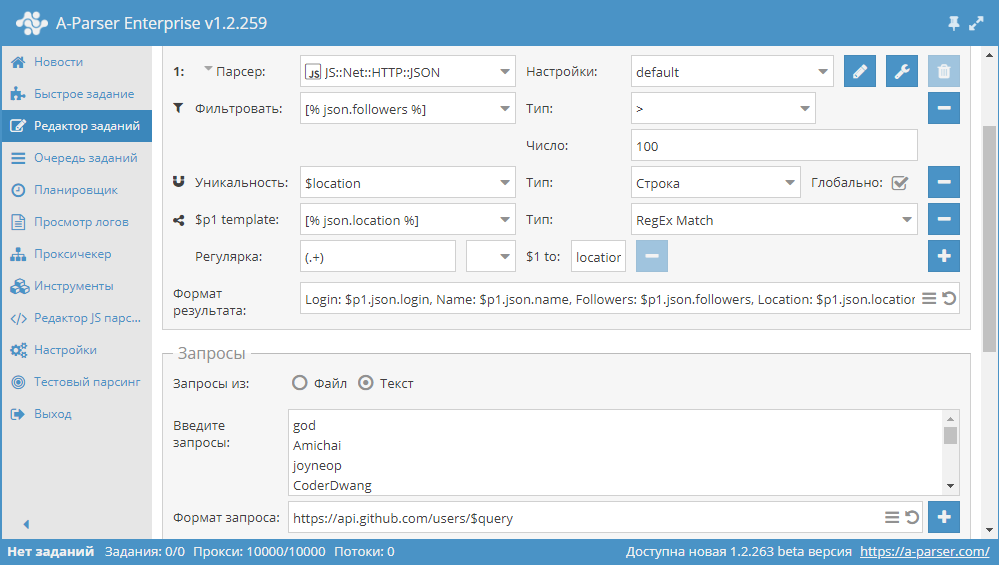
 Парсинг JSON ответов и работа с их содержимым
Парсинг JSON ответов и работа с их содержимым
JSON - это довольно популярный способ предоставления данных, который, например, часто используется при работе с API различных сервисов. В А-Парсере есть встроенные инструменты для работы с ним, но не всегда их применение может быть простым, иногда требуется дополнительно писать сложные шаблоны, используя шаблонизатор. Поэтому в статье по ссылке выше будет рассказано, как написать простой универсальный парсер JSON.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки ) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники статей
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 23/07/18 в 11:23 |
Видео урок: Создание JS парсеров. Работа с SQLite
Продолжение цикла уроков по созданию JavaScript парсеров. В этом видео показано, как работать с базой данных SQLite в JS парсере.
 В этом уроке рассмотрены:
В этом уроке рассмотрены:
- Знакомство с языком запросов SQL
- Создание простейшей базы данных SQLite при работе с JS-парсером
- Получение и запись данных в базу SQLite при работе с JS-парсером
Ссылки:
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 02/08/18 в 10:42 |
1.2.270 - новый парсер Rank::Curlie, множество доработок в Node.js функционале
 Улучшения
Исправления в связи с изменениями в выдаче
Исправления
Улучшения
Исправления в связи с изменениями в выдаче
Исправления
- Исправлена проблема с запуском на некоторых linux дистрибутивах
- Исправлена загрузка node.js модулей в редких случаях на Windows
- JS парсеры: добавлена поддержка dns.lookup и улучшена совместимость с модулем mysql2
- JS парсеры: исправлен util.promisify
- Исправлена работа некоторых Node.js модулей
- В SE::Google::Modern и SE::Bing $totalcount при 0 результатов теперь возвращает 0
- Исправлено логгирование в режиме foreground
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 13/08/18 в 11:56 |
25-й сборник рецептов
25-й сборник рецептов. В нем будет показан способ периодического парсинга с дозаписью результатов в таблицу, рассмотрен парсинг с помощью Node.js модуля Cheerio без использования регулярных выражений, а также показан парсер первой мобильной поисковой системы в Китае - Shenma. Поехали!
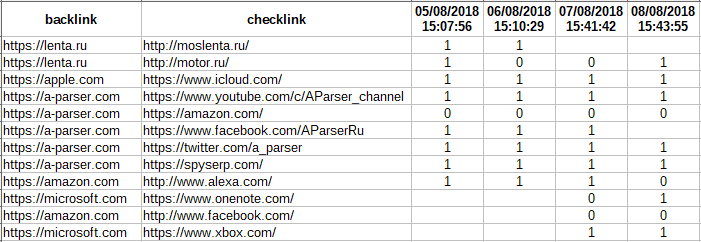
Периодическая проверка обратных ссылок с дозаписью результатов в таблицу
Пример решения одной из наиболее запрашиваемых задач - дозапись периодически получаемых результатов в одну и ту же таблицу. В качестве хранилища данных используется SQLite, при каждом запуске данные добавляются и выводятся в таблицу. Готовый пресет с комментариями - по ссылке выше.
 Парсер поисковой системы Haosou
Парсер поисковой системы Haosou
Как известно, в основе почти любого парсера используются регулярные выражения, реже - XPath. Работа с этими методами требует определенных знаний, что в свою очередь может вызывать некоторые сложности. Поэтому существуют и другие методы. Использование одного из них на примере парсинга популярного в Китае поисковика Haosou, показано по ссылке выше.
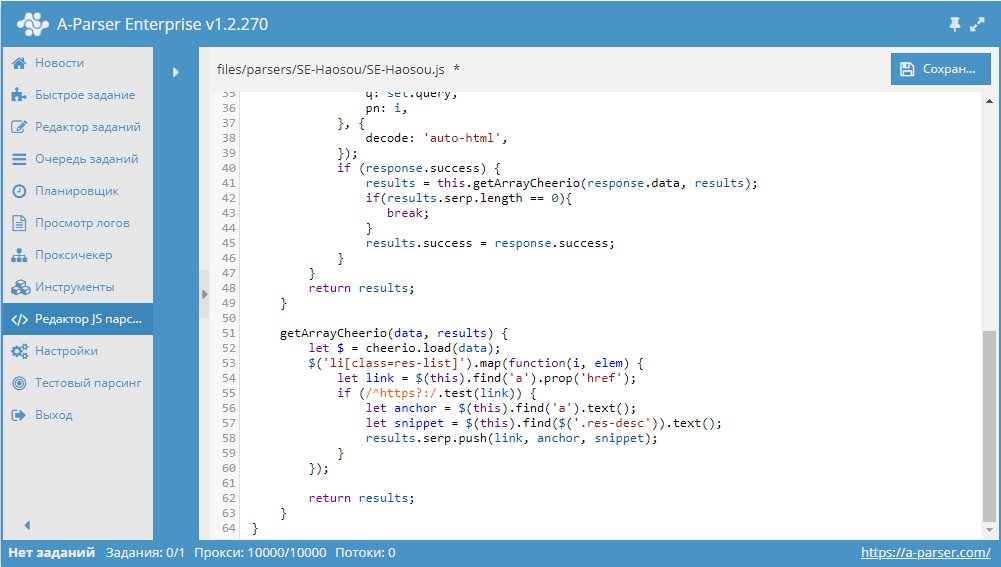 Парсер китайского поисковика Shenma
Парсер китайского поисковика Shenma
Еще один китайский поисковик в этом сборнике - Shenma. Это первая мобильная поисковая система в Китае, ориентирована в первую очередь на мобильные сайты. Пресет - по ссылке выше.
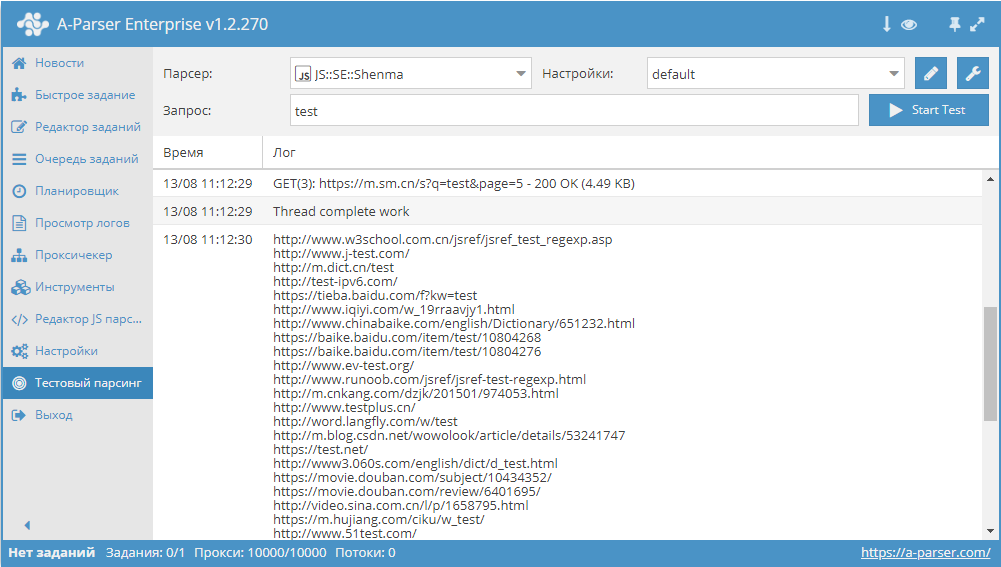 Еще больше различных рецептов в нашем Каталоге!
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники рецептов:
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
- Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
- Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
- Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
- Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
- Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
- Сборник рецептов #21: уведомления в Telegram из A-Parser, мультифильтр и парсинг IMDb
- Сборник рецептов #22: проверка индексации в нескольких ПС, многоуровневый парсинг и поиск сабдоменов
- Сборник рецептов #23: категории сайтов, парсинг в YML и преобразование дат
- Сборник рецептов #24: уведомление в Telegram об экспайре доменов, чекер РКН и работа с SQLite
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 23/08/18 в 11:29 |
Видео урок: Создание JS парсеров. Реализация подстановки запросов и их многопоточной обработки.
Продолжение цикла уроков по созданию JavaScript парсеров. В этом видео будет показано, как "на лету" добавлять запросы в задание и многопоточно их обрабатывать.
В одной из наших статей мы рассмотрели способ разработки парсера, который собирает ТОП 10 из выдачи поисковика, а затем по очереди парсит нужные данные по полученным ссылкам. Вроде все неплохо, но если у вас не 10 запросов, несколько тысяч? Задание будет выполняться очень долго, а время это самый драгоценный и не восполняемый ресурс.
К счастью в A-Parser есть такая замечательная вещь, как многоуровневый парсинг, который позволяет многократно увеличить скорость парсинга, и в этом видео мы рассмотрим как этой возможностью пользоваться.
В этом уроке рассмотрено:
- Реализация раздельных процедур парсинга в зависимости от внешних условий, а именно - уровня парсинга
- Подстановка запросов в задание "на лету"
- Использование стандартных парсеров в кастомных JavaScript парсерах
Ссылки:
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
С нами с 03.06.13
Сообщения: 309
Рейтинг: 37
|
| Добавлено: 13/09/18 в 18:39 |
Сборник статей #5: собственный канал в Telegram и массовое добавление товаров в OpenCart
В 5-м сборнике статей на реальном примере будет показано, как создать свой канал в Телеграме и полностью автоматизировать его наполнение контентом. Также мы продолжаем цикл статей по работе с OpenCart и во 2-й части будет рассмотрен вопрос массового добавления товаров. Как обычно, в каждой статье приложены готовые JS парсеры, используя которые, можно на реальных примерах изучить описанные методы и поэксперементировать с ними. Поехали!
Полноценный Telegram канал на базе A-Parser
В этой статье будет описан способ создания полноценного канала в Telegram c автоматизированным сбором контента и постингом сообщений через заданные интервалы. И конечно, все это на базе A-Parser. Все подробности, а также готовые пресеты - по ссылке выше.
 Работаем с OpenCart. Часть 2. Массовое добавление товаров
Работаем с OpenCart. Часть 2. Массовое добавление товаров
Мы продолжаем цикл статей о заливке товаров в интернет-магазин на базе OpenCart. Во второй части будет рассмотрено массовое добавление товара. Подробности, а также пример готового парсера - по ссылке выше.

Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки ) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники статей
|
|
|
|
A-Parser - парсер для профессионалов SEO
SpySerp.com - бесплатный сервис отслеживания позиций
|
0
|
|
| |
Текстовая реклама в форме ответа
Заголовок и до четырех строчек текста
Длина текста до 350 символов
Купить рекламу в этом месте! |
|
Спонсор сайта


|